How to Build LLM Streams That Survive Reconnects, Refreshes, and Crashes

What We're Building
In this article, we're building extremely durable LLM streams that easily survive:
- Network outages
- Page refreshes
- Closing the website
- Closing the laptop lid
Bonus: You can view the same stream on multiple devices (e.g. phone and laptop) at the same time.
No matter how hard you try to break the stream, it continues in the background while you're disconnected and smoothly continues when you're back. This is an incredible user experience.
Durable LLM streams demo 👇
Inspiration
When building with AI, it's a best practice to stream AI responses in real-time.
Instead of waiting for the whole response, your user sees the content in real-time as it's generated - which is amazing for UX. Tools like the AI SDK by Vercel have made this extremely easy:
import { openai } from "@ai-sdk/openai";
import { streamText } from "ai";
const { textStream } = streamText({
model: openai("gpt-4o"),
prompt: "Invent a new holiday and describe its traditions.",
});To make real-time LLM streams work on a technical level, you connect a client to an API and stream data back using protocols like Server Sent Events (SSE):
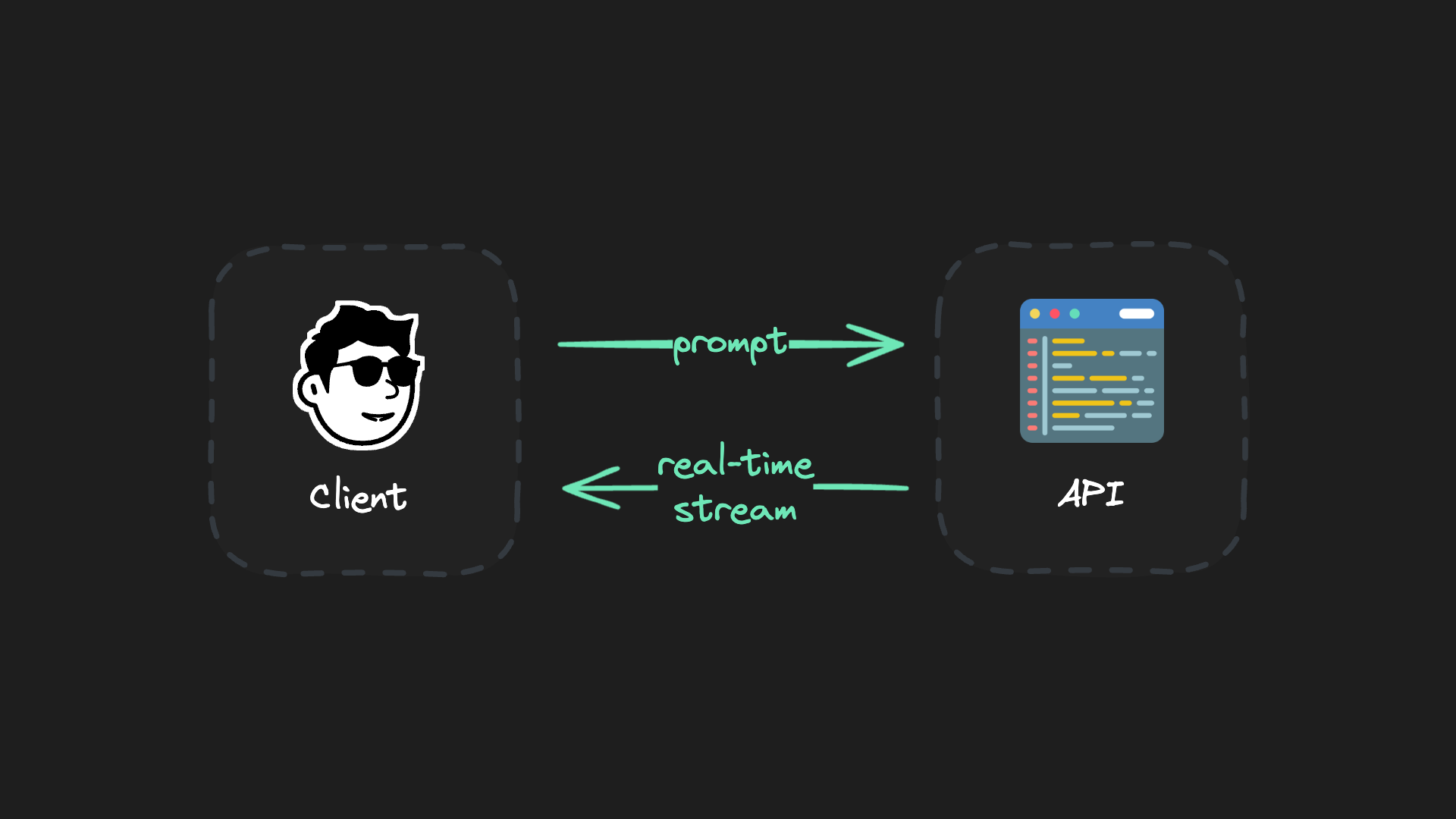
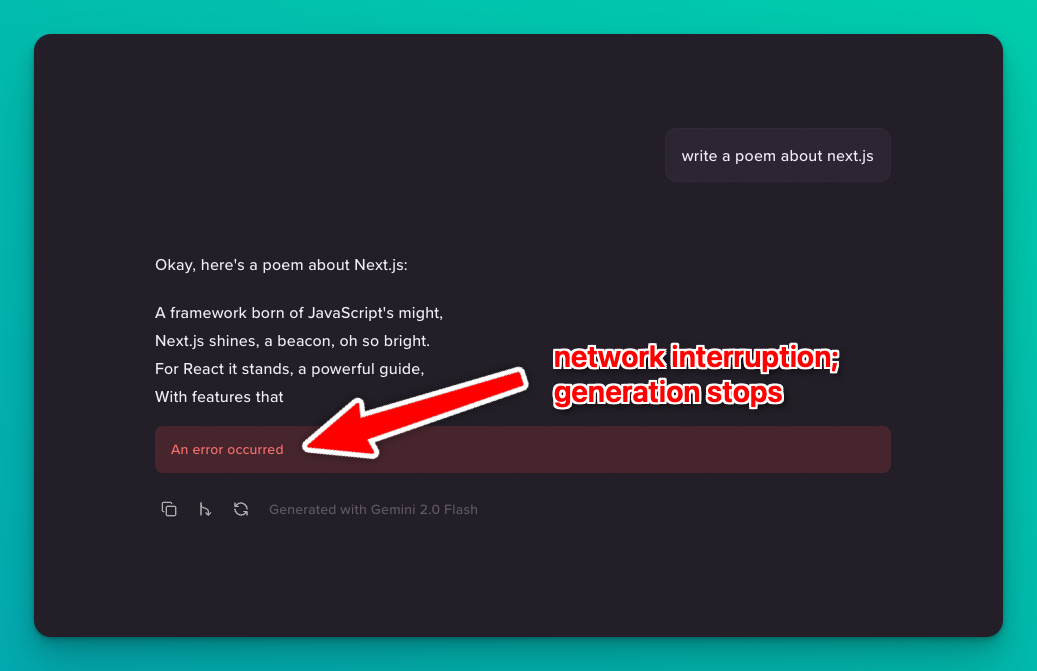
But: this setup has a problem.
If anything happens during the stream, like your internet disconnecting, shutting the laptop lid, or a network hiccup, the entire generation is lost. You need to start over and wait for the entire generation again. This is especially annoying for longer generations (e.g. with expensive-to-run models like O1).
Obviously this problem is on people's radar. There's real demand for reliable real-time LLM streaming, and more devs are experimenting with ways to make it work:
Building High-Durability LLM Streams
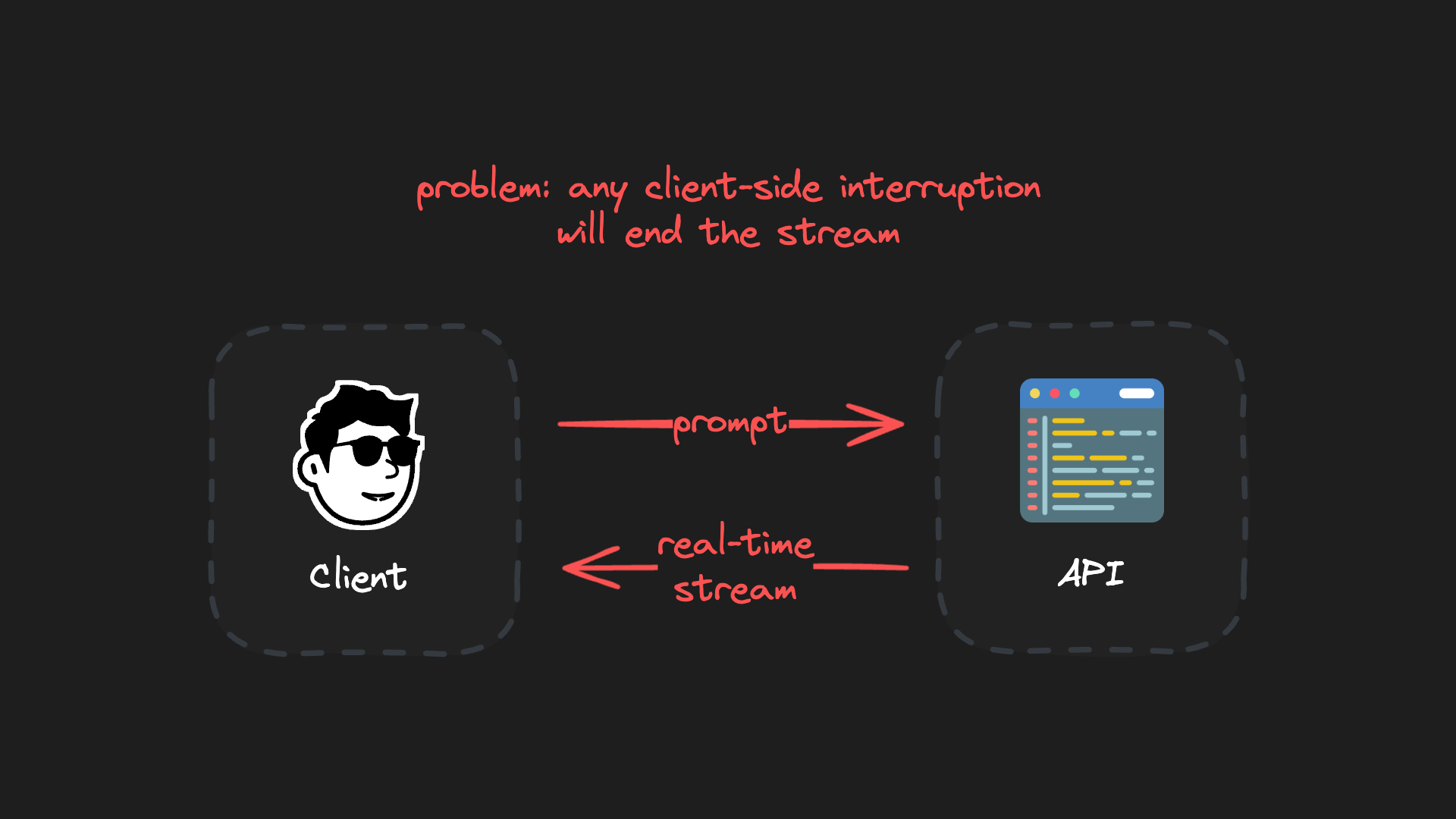
The secret sauce for creating truly durable, resumable LLM streams is separating the client from the generation environment. Client connections are unstable and can be disconnected for many reasons, like closing a laptop, network problems or refreshing a page.
By keeping the client and generation processes separate, the generation always continues uninterrupted. Clients can reconnect at any time-without interrupting the ongoing generation.
Bad idea: Persistent, direct connection:
Good idea: Replaceable, interruptible stream connection:
And yes - this architecture might look pretty complex for a simple AI stream. As you'll see in the code right now though, this is only a few lines of code and takes a few minutes to implement.
Setting up Durable Streams
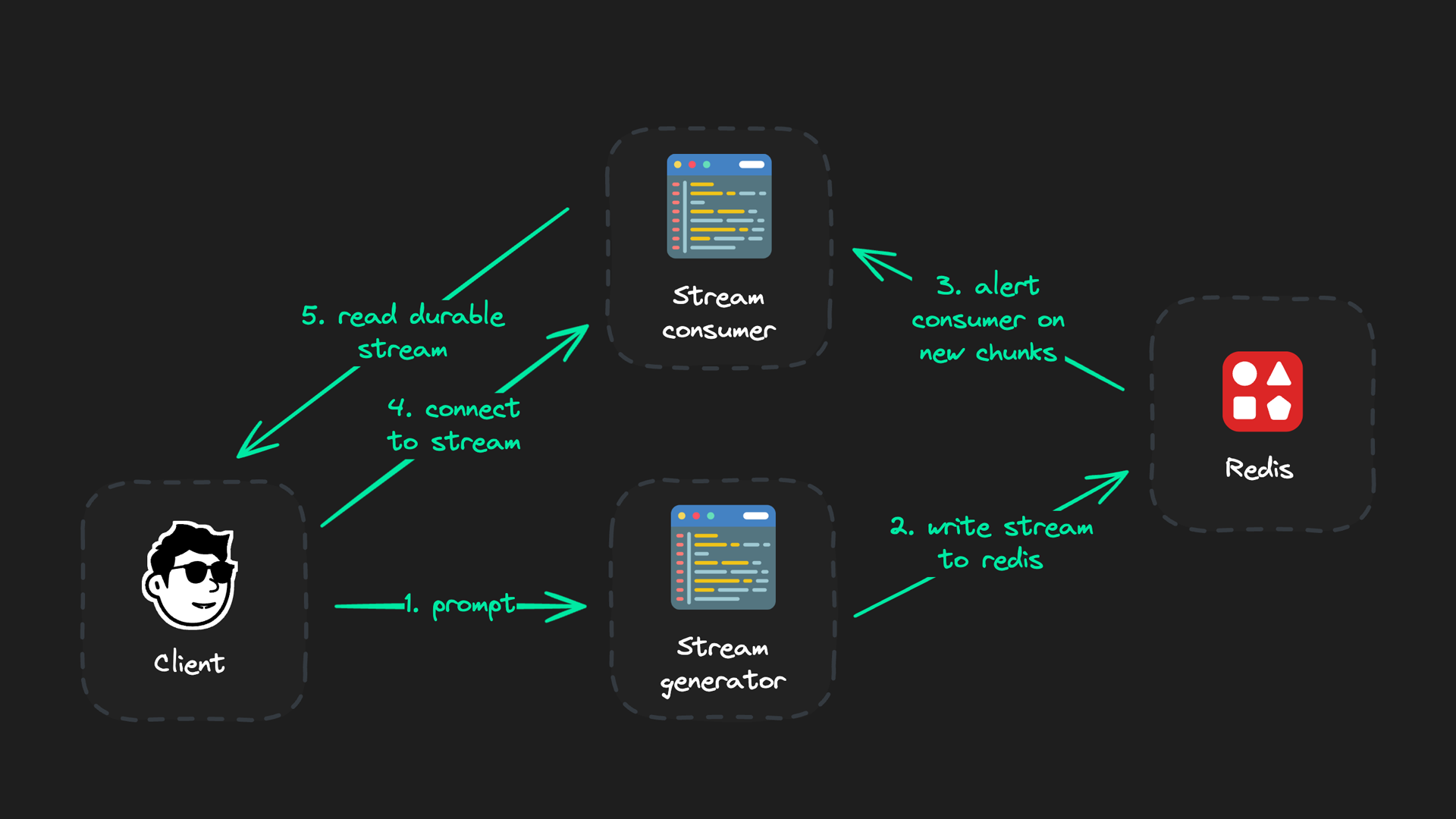
An extremely reliable LLM stream setup has three parts:
- The client (frontend)
- The stream generator (an API route)
- The stream consumer (also an API route)
All connections directly to the client can be interrupted or paused at any time. The piece of logic responsible for generating the LLM output stream (the stream generator) therefore should be an independent API that never has an active connection to the client.
Instead, we'll connect to the client via a consumer - that just reads data from Redis and is otherwise pretty "stupid". Its only purpose is to read the generator's output and provide all LLM chunks a client hasn't seen yet whenever a client connects to it. That's it.
Quick summary - what each part does:
- Client: Triggers stream generator (but never maintains open connection) and renders real-time stream
- Stream generator: Generates LLM output in real-time and publishes to Redis
- Stream consumer: Reads the generator's stream and pushes chunks to client
The generator is only responsible for reading an LLM stream and publishing it to Redis in real-time. We get a replaceable connection from client to stream consumer that can be ended, reconnected, etc.-nothing affects stream generator.
Code Examples
In this section, we'll take a look at code. To make the principles very clear, we'll look at the actual, complete production code implementation at the end.
For now, it's much easier to understand the code if we take a look at the core snippets and their purpose instead of entire code files.
1. The Client
The client only has 3 responsibilities:
- Generating session IDs
- Triggering the generator
- Rendering the generation stream
Let's look at each one:
Client: Generating Session IDs
When a client connects or reconnects to a stream, we want to send all messages that the client has not yet seen. That means that during an active stream, each message only contains the exact delta the client needs to see and not the entire stream.
When reconnecting, the entire stream up to the current generation point is sent and the subscription to all future events is absolutely seamless without any missing chunks.
How?
Redis Streams, a way to efficiently store and retrieve real-time data, have this not-yet-seen functionality built in through something called consumer groups. The only thing we need to do: make sure each client has a unique session - meaning we assign each generation a unique ID.
We'll learn more about consumer groups when looking at the stream consumer. They look like this:
await redis.xgroup("redis-key", {
type: "CREATE",
group: "my-group-name",
id: "0",
});The entire logic of which client has seen which stream up until which point and which pieces are missing is entirely handled by Redis streams with guaranteed precision. We never get a missing LLM chunk and always send exactly the data a client needs.
The only thing the client needs to do for now: assign an ID for each generation. We simply use nanoid:
import { customAlphabet } from "nanoid"
const nanoid = customAlphabet("0123456789", 6);Client: Triggering a Generation Stream
The only interaction a client ever has to the generation engine is triggering it. Technically though, you could trigger the generation from anywhere else (e.g. CRON jobs, automated pipelines).
In its simplest form, this is just a fetch call to the generation API route:
// 👇 trigger stream generator
await fetch("/api/llm-stream", {
method: "POST",
headers: {
"Content-Type": "application/json",
},
body: JSON.stringify({ prompt, sessionId }),
});Client: Reading a Generation Stream
After triggering the generation, the generator starts streaming LLM output into a centralized Redis store-completely decoupled from the client. Let's connect to the stream consumer to read the generation stream:
// 👇 connect to stream consumer
const res = await fetch(`/api/check-stream?sessionId=${sessionId}`, {
headers: { "Content-Type": "text/event-stream" },
});That's it!
Those are the client's three responsibilities. Of course, we can get much fancier with custom hooks for ID generation, react-query for additional reliability and more - we'll get to that in the complete code examples later.
2. The Stream Generator
The stream generator opens an LLM stream and writes each chunk to a Redis stream. It publishes a message for every chunk written to alert the stream consumer about new data for real-time updates.
Note: Again, this is intentionally not a full code example. We'll get to the full code at the end-this is to understand the concept.
import { streamText } from "ai"
import { redis } from "@/utils"
const result = await new Promise(
async (resolve, reject) => {
const { textStream } = streamText({
model: openai("gpt-4o"),
prompt,
onError: (err) => reject(err),
onFinish: async () => {
resolve({
// ...
}),
})
for await (const chunk of textStream) {
if (chunk) {
const chunkMessage: ChunkMessage = {
type: MessageType.CHUNK,
content: chunk,
}
// 👇 write chunk to redis stream
await redis.xadd(streamKey, "*", chunkMessage)
// 👇 alert consumer that there's a new chunk
await redis.publish(streamKey, { type: MessageType.CHUNK })
}
}
}
)3. The Stream Consumer
The stream consumer connects to Redis and listens to new chunk alerts via Redis pub/sub. Each client gets their own consumer group to track its seen and unseen messages.
Note: The publish doesn't transfer the actual chunk, it just alerts that a new chunk is available in the stream.
When a new chunk is available, the stream consumer API reads it from the stream and forwards it to all connected clients. Redis consumer groups track what each client has seen to guarantee transferring no duplicates or missing chunks.
The core stream consumer looks like this:
const streamKey = `llm:stream:${sessionId}`;
const groupName = `sse-group-${nanoid()}`;
await redis.xgroup(streamKey, {
type: "CREATE",
group: groupName,
id: "0",
});
const readStreamMessages = async () => {
const chunks = (await redis.xreadgroup(
groupName,
`consumer-1`,
streamKey,
// 👇 built-in Redis stream functionality: only send unseen messages
">",
)) as StreamData[];
if (chunks?.length > 0) {
const [_streamKey, messages] = chunks[0];
for (const [_messageId, fields] of messages) {
const rawObj = arrToObj(fields);
const validatedMessage = validateMessage(rawObj);
if (validatedMessage) {
controller.enqueue(json(validatedMessage));
}
}
}
};
// 👇 initial read
await readStreamMessages();
const subscription = redis.subscribe(streamKey);
subscription.on("message", async () => {
// 👇 read every time a new chunk is written to stream
await readStreamMessages();
});Note: We're creating a consumer group on every connection. This works so well because Redis handles this operation idempotently, e.g. nothing happens if the group already exists.
Full Code
SessionID generation
Until now, we've looked at individual pieces of code to understand the clients' tasks, the stream generator and the stream consumer individually. Now, let's take a look at how these pieces fit together by seeing the full implementation.
To start off, creating a sessionId should be more resilient than just using nanoid(). After all, what if the website is refreshed or closed? Upon reconnect, we'd lose the generated sessionId if we don't store it somewhere - it needs to be persisted for as long as the generation runs.
Luckily localStorage is perfect for this:
import { customAlphabet } from "nanoid";
import { useRouter } from "next/navigation";
import { useCallback, useEffect, useState } from "react";
export const useLLMSession = () => {
const [sessionId, setSessionId] = useState<string>("");
const router = useRouter();
const nanoid = customAlphabet("0123456789", 6);
const updateUrlWithSessionId = useCallback(
(id: string) => {
const url = new URL(window.location.href);
url.searchParams.set("sessionId", id);
router.replace(url.toString(), { scroll: false });
},
[router],
);
useEffect(() => {
const urlParams = new URLSearchParams(window.location.search);
const urlSessionId = urlParams.get("sessionId");
const storedSessionId = localStorage.getItem("llm-session-id");
if (urlSessionId) {
localStorage.setItem("llm-session-id", urlSessionId);
setSessionId(urlSessionId);
} else if (storedSessionId) {
setSessionId(storedSessionId);
updateUrlWithSessionId(storedSessionId);
} else {
const newSessionId = nanoid();
localStorage.setItem("llm-session-id", newSessionId);
setSessionId(newSessionId);
updateUrlWithSessionId(newSessionId);
}
// eslint-disable-next-line react-hooks/exhaustive-deps
}, []);
const clearSessionId = useCallback(() => {
localStorage.removeItem("llm-session-id");
setSessionId("");
const url = new URL(window.location.href);
url.searchParams.delete("sessionId");
router.replace(url.toString(), { scroll: false });
}, [router]);
const regenerateSessionId = () => {
const newSessionId = nanoid();
localStorage.setItem("llm-session-id", newSessionId);
setSessionId(newSessionId);
updateUrlWithSessionId(newSessionId);
return newSessionId;
};
return {
sessionId,
regenerateSessionId,
clearSessionId,
};
};Client
We've already seen the two most important parts of the client: starting a stream and connecting to a stream. Once we've got a confirmation from our API that the generator is running, we connect to the stream using react-queries refetch utility to invoke our connection query.
Here's how all pieces fit together:
"use client"
import { useLLMSession } from "@/use-llm-session"
import { useMutation, useQuery } from "@tanstack/react-query"
import { FormEvent, useRef, useState, useEffect } from "react"
import {
MessageType,
validateMessage,
type ChunkMessage,
type MetadataMessage,
StreamStatus,
} from "@/lib/message-schema"
// precondition = stream is ready to read
class PreconditionFailedError extends Error {
constructor(message: string) {
super(message)
this.name = "PreconditionFailedError"
}
}
export default function Home() {
const { sessionId, regenerateSessionId, clearSessionId } = useLLMSession()
const [prompt, setPrompt] = useState("")
const [status, setStatus] = useState<
"idle" | "loading" | "streaming" | "completed" | "error"
>("idle")
const [response, setResponse] = useState("")
const [chunkCount, setChunkCount] = useState(0)
const controller = useRef<AbortController | null>(null)
const responseRef = useRef<HTMLDivElement>(null)
const isInitialRequest = useRef(true)
// keep generation in viewport
useEffect(() => {
if (responseRef.current) {
responseRef.current.scrollTop = responseRef.current.scrollHeight
}
}, [response])
// start generator
const { mutate, error, isIdle } = useMutation({
mutationFn: async (newSessionId: string) => {
controller.current?.abort()
isInitialRequest.current = false
await fetch("/api/llm-stream", {
method: "POST",
headers: {
"Content-Type": "application/json",
},
body: JSON.stringify({ prompt, sessionId: newSessionId }),
})
},
onSuccess: () => {
setStatus("streaming")
refetch()
},
})
// connect to running stream
const { refetch } = useQuery({
queryKey: ["stream", sessionId],
queryFn: async () => {
if (!sessionId) return null
setResponse("")
setChunkCount(0)
const abortController = new AbortController()
controller.current = abortController
const res = await fetch(`/api/check-stream?sessionId=${sessionId}`, {
headers: { "Content-Type": "text/event-stream" },
signal: controller.current.signal,
})
if (res.status === 412) {
// stream is not yet ready, retry connection
throw new PreconditionFailedError("Stream not ready yet")
}
if (!res.body) return null
const reader = res.body.pipeThrough(new TextDecoderStream()).getReader()
let streamContent = ""
while (true) {
const { value, done } = await reader.read()
if (done) break
if (value) {
const messages = value.split("\n\n").filter(Boolean)
for (const message of messages) {
if (message.startsWith("data: ")) {
const data = message.slice(6)
try {
const parsedData = JSON.parse(data)
const validatedMessage = validateMessage(parsedData)
if (!validatedMessage) continue
switch (validatedMessage.type) {
case MessageType.CHUNK:
const chunkMessage = validatedMessage as ChunkMessage
streamContent += chunkMessage.content
setResponse((prev) => prev + chunkMessage.content)
setChunkCount((prev) => prev + 1)
break
case MessageType.METADATA:
const metadataMessage = validatedMessage as MetadataMessage
if (metadataMessage.status === StreamStatus.COMPLETED) {
setStatus("completed")
}
break
case MessageType.ERROR:
setStatus("error")
break
}
} catch (e) {
console.error("Failed to parse message:", e)
}
}
}
}
}
return streamContent
},
refetchOnWindowFocus: false,
refetchOnMount: false,
retry(failureCount, error) {
if (isInitialRequest.current === true) return false
if (error instanceof PreconditionFailedError) {
return failureCount < 10
}
return false
},
})
const handleSubmit = async (e: FormEvent) => {
e.preventDefault()
setStatus("loading")
const newSessionId = regenerateSessionId()
mutate(newSessionId)
}
const handleReset = () => {
controller.current?.abort()
clearSessionId()
setPrompt("")
setResponse("")
setChunkCount(0)
setStatus("idle")
}
return (
<main className="flex min-h-screen flex-col items-center justify-between p-12 sm:p-24">
<div className="z-10 max-w-5xl w-full items-center justify-between font-mono text-sm">
<h1 className="text-4xl tracking-tight font-bold mb-8 text-center">
Resumable LLM Stream
</h1>
<form onSubmit={handleSubmit} className="mb-8">
<div className="mb-4">
<label htmlFor="prompt" className="block text-sm font-medium mb-2">
Enter your prompt:
</label>
<textarea
autoFocus
id="prompt"
value={prompt}
onChange={(e) => setPrompt(e.target.value)}
className="w-full p-2 border border-zinc-700 rounded-md min-h-[100px] focus:outline-none focus:ring-2 focus:ring-blue-500 focus:border-transparent transition-all duration-200"
placeholder="Ask the AI something..."
disabled={status === "loading" || status === "streaming"}
/>
</div>
<div className="flex gap-4">
<button
type="submit"
disabled={status === "loading" || status === "streaming"}
className="px-4 py-2 bg-blue-600 text-white rounded-md hover:bg-blue-700 disabled:bg-gray-400"
>
{status === "loading"
? "Starting..."
: status === "streaming"
? "Streaming..."
: "Generate Response"}
</button>
<button
type="button"
onClick={handleReset}
className="px-4 py-2 bg-zinc-600 text-white rounded-md hover:bg-zinc-700"
>
Reset
</button>
</div>
</form>
<div className="mt-8">
<h2 className="text-xl tracking-tight font-semibold mb-2">
Response:
</h2>
{status === "error" ? (
<div className="p-4 bg-red-100 border border-red-300 rounded-md text-red-800">
<p className="font-bold">Error:</p>
<p>{error?.message}</p>
</div>
) : status === "idle" && !response ? (
<p className="text-gray-500">
Enter a prompt and click "Generate Response" to see the AI's
response.
</p>
) : (
<div
ref={responseRef}
className="flex flex-col h-96 overflow-y-auto p-4 bg-zinc-900 text-zinc-200 border border-zinc-800 rounded-md whitespace-pre-wrap [&::-webkit-scrollbar]:w-2 [&::-webkit-scrollbar-thumb]:bg-zinc-700 [&::-webkit-scrollbar-track]:bg-zinc-800"
>
<div>{response || "Loading..."}</div>
</div>
)}
{(status === "streaming" || status === "completed") && (
<div className="mt-2 text-sm text-gray-500">
<p>Session ID: {sessionId}</p>
<p>Status: {status}</p>
<p>Chunks received: {chunkCount}</p>
<p>
Connection: {status === "streaming" ? "Active SSE" : "Closed"}
</p>
</div>
)}
</div>
</div>
</main>
)
}Stream Generator
Here's the entire code for the stream generator. If an LLM generation fails at any point, it's automatically retried using Upstash Workflow for maximum reliability:
import {
MessageType,
StreamStatus,
type ChunkMessage,
type MetadataMessage,
} from "@/lib/message-schema";
import { redis } from "@/utils";
import { openai } from "@ai-sdk/openai";
import { serve } from "@upstash/workflow/nextjs";
import { streamText } from "ai";
interface LLMStreamResponse {
success: boolean;
sessionId: string;
totalChunks: number;
fullContent: string;
}
export const { POST } = serve(async (context) => {
const { prompt, sessionId } = context.requestPayload as {
prompt?: string;
sessionId?: string;
};
if (!prompt || !sessionId) {
throw new Error("Prompt and sessionId are required");
}
const streamKey = `llm:stream:${sessionId}`;
await context.run("mark-stream-start", async () => {
const metadataMessage: MetadataMessage = {
type: MessageType.METADATA,
status: StreamStatus.STARTED,
completedAt: new Date().toISOString(),
totalChunks: 0,
fullContent: "",
};
await redis.xadd(streamKey, "*", metadataMessage);
await redis.publish(streamKey, { type: MessageType.METADATA });
});
const res = await context.run("generate-llm-response", async () => {
const result = await new Promise<LLMStreamResponse>(
async (resolve, reject) => {
let fullContent = "";
let chunkIndex = 0;
const { textStream } = streamText({
model: openai("gpt-4o"),
prompt,
onError: (err) => reject(err),
onFinish: async () => {
resolve({
success: true,
sessionId,
totalChunks: chunkIndex,
fullContent,
});
},
});
for await (const chunk of textStream) {
if (chunk) {
fullContent += chunk;
chunkIndex++;
const chunkMessage: ChunkMessage = {
type: MessageType.CHUNK,
content: chunk,
};
await redis.xadd(streamKey, "*", chunkMessage);
await redis.publish(streamKey, { type: MessageType.CHUNK });
}
}
},
);
return result;
});
await context.run("mark-stream-end", async () => {
const metadataMessage: MetadataMessage = {
type: MessageType.METADATA,
status: StreamStatus.COMPLETED,
completedAt: new Date().toISOString(),
totalChunks: res.totalChunks,
fullContent: res.fullContent,
};
await redis.xadd(streamKey, "*", metadataMessage);
await redis.publish(streamKey, { type: MessageType.METADATA });
});
});For complete type-safety, I also wrote all message schemas in zod:
import { z } from "zod";
export const MessageType = {
CHUNK: "chunk",
METADATA: "metadata",
EVENT: "event",
ERROR: "error",
} as const;
export const StreamStatus = {
STARTED: "started",
STREAMING: "streaming",
COMPLETED: "completed",
ERROR: "error",
} as const;
export const baseMessageSchema = z.object({
type: z.enum([
MessageType.CHUNK,
MessageType.METADATA,
MessageType.EVENT,
MessageType.ERROR,
]),
});
export const chunkMessageSchema = baseMessageSchema.extend({
type: z.literal(MessageType.CHUNK),
content: z.string(),
});
export const metadataMessageSchema = baseMessageSchema.extend({
type: z.literal(MessageType.METADATA),
status: z.enum([
StreamStatus.STARTED,
StreamStatus.STREAMING,
StreamStatus.COMPLETED,
StreamStatus.ERROR,
]),
completedAt: z.string().optional(),
totalChunks: z.number().optional(),
fullContent: z.string().optional(),
error: z.string().optional(),
});
export const eventMessageSchema = baseMessageSchema.extend({
type: z.literal(MessageType.EVENT),
});
export const errorMessageSchema = baseMessageSchema.extend({
type: z.literal(MessageType.ERROR),
error: z.string(),
});
export const messageSchema = z.discriminatedUnion("type", [
chunkMessageSchema,
metadataMessageSchema,
eventMessageSchema,
errorMessageSchema,
]);
export type Message = z.infer<typeof messageSchema>;
export type ChunkMessage = z.infer<typeof chunkMessageSchema>;
export type MetadataMessage = z.infer<typeof metadataMessageSchema>;
export type EventMessage = z.infer<typeof eventMessageSchema>;
export type ErrorMessage = z.infer<typeof errorMessageSchema>;
export const validateMessage = (data: unknown): Message | null => {
const result = messageSchema.safeParse(data);
return result.success ? result.data : null;
};Stream Consumer
Lastly, let's take a look at the full stream consumer implementation. This is the replaceable connection that automatically sends along all unseen chunks when a client connects:
import { redis } from "@/utils"
import { nanoid } from "nanoid"
import { NextRequest, NextResponse } from "next/server"
import {
validateMessage,
MessageType,
type ErrorMessage,
} from "@/lib/message-schema"
export const dynamic = "force-dynamic"
export const maxDuration = 60
export const runtime = "nodejs"
type StreamField = string
type StreamMessage = [string, StreamField[]]
type StreamData = [string, StreamMessage[]]
const arrToObj = (arr: StreamField[]) => {
const obj: Record<string, string> = {}
for (let i = 0; i < arr.length; i += 2) {
obj[arr[i]] = arr[i + 1]
}
return obj
}
const json = (data: Record<string, unknown>) => {
return new TextEncoder().encode(`data: ${JSON.stringify(data)}\n\n`)
}
export async function GET(req: NextRequest) {
const { searchParams } = new URL(req.url)
const sessionId = searchParams.get("sessionId")
if (!sessionId) {
return NextResponse.json(
{ error: "Stream key is required" },
{ status: 400 }
)
}
const streamKey = `llm:stream:${sessionId}`
const groupName = `sse-group-${nanoid()}`
const keyExists = await redis.exists(streamKey)
if (!keyExists) {
return NextResponse.json(
{ error: "Stream does not (yet) exist" },
{ status: 412 }
)
}
try {
await redis.xgroup(streamKey, {
type: "CREATE",
group: groupName,
id: "0",
})
} catch (_err) {}
const response = new Response(
new ReadableStream({
async start(controller) {
const readStreamMessages = async () => {
const chunks = (await redis.xreadgroup(
groupName,
`consumer-1`,
streamKey,
">"
)) as StreamData[]
if (chunks?.length > 0) {
const [_streamKey, messages] = chunks[0]
for (const [_messageId, fields] of messages) {
const rawObj = arrToObj(fields)
const validatedMessage = validateMessage(rawObj)
if (validatedMessage) {
controller.enqueue(json(validatedMessage))
}
}
}
}
await readStreamMessages()
const subscription = redis.subscribe(streamKey)
subscription.on("message", async () => {
await readStreamMessages()
})
subscription.on("error", (error) => {
console.error(`SSE subscription error on ${streamKey}:`, error)
const errorMessage: ErrorMessage = {
type: MessageType.ERROR,
error: error.message,
}
controller.enqueue(json(errorMessage))
controller.close()
})
req.signal.addEventListener("abort", () => {
console.log("Client disconnected, cleaning up subscription")
subscription.unsubscribe()
controller.close()
})
},
}),
{
headers: {
"Content-Type": "text/event-stream",
"Cache-Control": "no-cache, no-transform",
Connection: "keep-alive",
},
}
)
return response
}Quick Summary & Final Words
We've just built an extremely robust LLM stream that can handle network interruptions, page refreshes, and even complete disconnections. Here's what we did:
-
Decoupled generation from delivery: By separating LLM generation from the client connection, the content generation continues regardless of client problems.
-
Persistent storage using Redis streams: We're using Redis streams as a persistent message broker to store each chunk of the LLM response as it's generated.
-
Real-time Updates with Redis Pub/Sub: We've built a notification system using Redis Pub/Sub to notify stream consumers when new chunks are available.
-
Automatic reconnection: The client can reconnect at any time and automatically receives all content, guaranteed without duplicates or missing chunks. This includes content generated during the disconnect.
-
Session Management: We created a session system that allows users to view streams on multiple devices at the same time.
Bottom line, we're now providing an exceptional user experience (UX) to our users. I really recommend this approach, especially if you're building something like an LLM chat service.
Cheers for reading! If you have any feedback or would like to be a guest author on Upstash, reach out at josh@upstash.com 🙌