Building Smart Autocomplete with Redis Sorted Sets

Have you ever noticed how search boxes suggest words as you type? Turns out, most of these suggestions show up in a simple alphabetical order and aren't super helpful.
But what if a search box could get smarter over time?
Learning from what people actually click on and showing the most popular results first?
This is what we'll build:
We'll see how Redis Sorted Sets can power an intelligent autocomplete system that learns from user behavior and becomes more accurate (shows popular results first) over time.
The Idea of Smart Autocomplete Systems
A basic search box would use a method called prefix matching to decide which results to show first.
As you type, it shows matches in A-Z order. It doesn't actually care which results people actually click on the most.
We're going to make it smarter. Our search box will learn from what people choose. When people click on a search result, we'll show that result first next time.
This means our search gets better and more helpful over time by automatically showing the most popular results at the top.
Why This Matters for Search Applications
Consider a movie search application: when users type "int". They might see:
- "Interceptor"
- "Interstate 60"
- "Interstellar"
In a "traditional" system, these would appear alphabetically. However, if users consistently click on "Interstellar", we'd want to promote it to the top of the autocomplete suggestions.
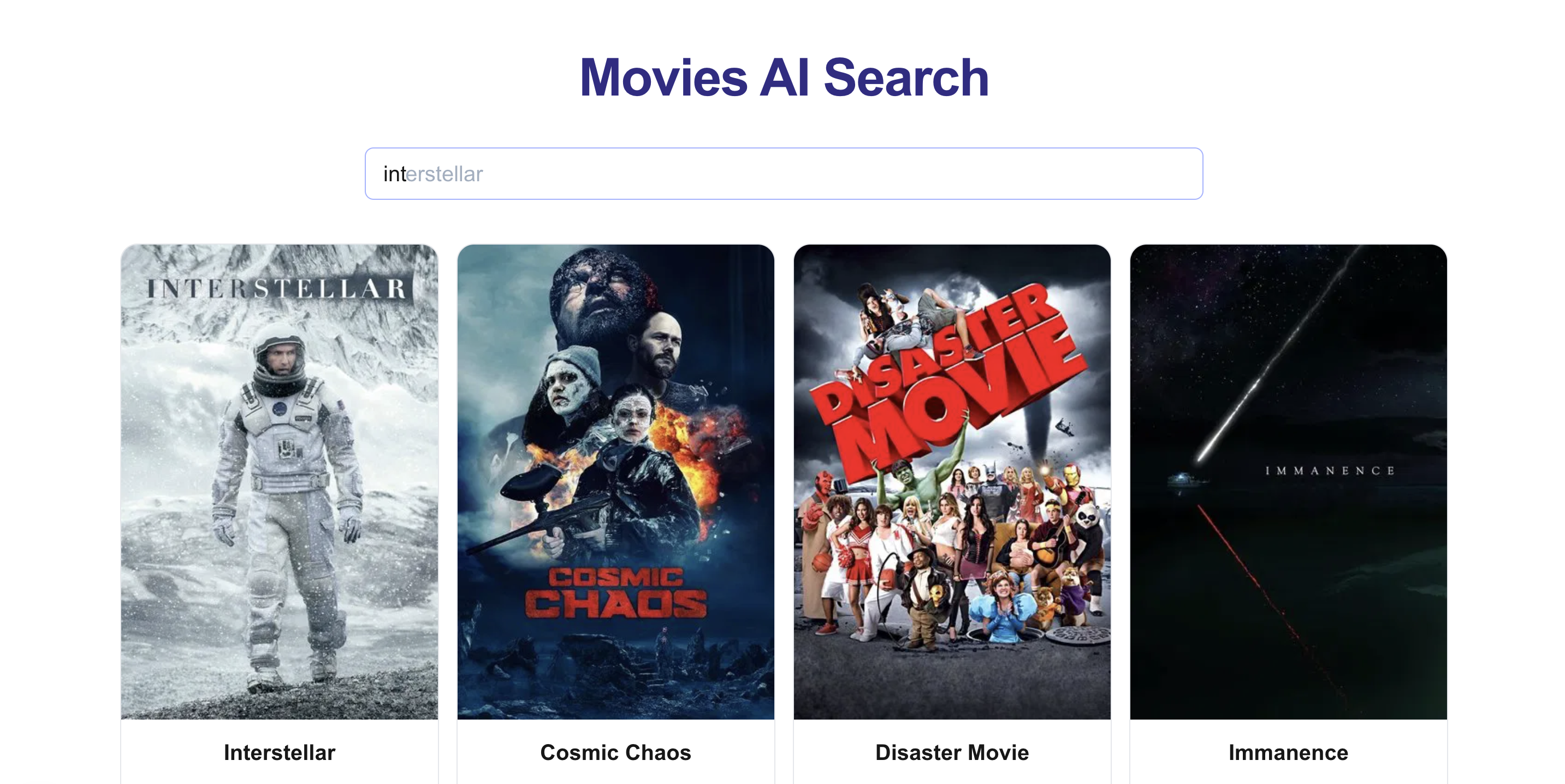
This smart ranking system works really well for:
- Streaming services like Netflix or YouTube to show what people are watching most
- Online stores to show popular products first when searching
- Help centers to show the most common questions people ask
- Any website with search to show what most people click on first
Understanding Redis Sorted Sets
Let's understand why Redis Sorted Sets are great for building an autocomplete system.
A Redis Sorted Set is like a smart list where:
- Each item is unique (like a set)
- Each item has a score (for ordering)
- Items can be quickly sorted by their scores
For our autocomplete system, we'll use two sorted sets:
- One for matching text prefixes (e.g. "int" matches "interstellar")
- Another for tracking how popular each suggestion is
These two sets work together to suggest the most relevant results as users type.
The Foundation: Alphabetical Ordering
Redis Sorted Sets maintain alphabetical ordering when all members have the same score. This is perfect for building search suggestions because it lets us:
- Store all prefixes of searchable terms in a single data structure
- Use
ZRANKto find the starting position of any prefix in O(log N) time - Use
ZSCANto efficiently retrieve all matches beginning from that position - Use
ZMSCOREto get the popularity score of each match - Use
ZINCRBYto increment the popularity score of each match
Let's look at a simple example. When we add the movie "INTERSTELLAR" to our search system, we break it down like this:
- Score: 0, Member: "I"
- Score: 0, Member: "IN"
- Score: 0, Member: "INT"
- Score: 0, Member: "INTE"
- Score: 0, Member: "INTER"
- Score: 0, Member: "INTERSTELLAR$Interstellar" (complete entry with display format)
See how we use $ to split the search version from the display version? This way, users can search without worrying about uppercase or lowercase letters, but we still show the movie title exactly how it should look.
How We Store the Data
We use two Redis sorted sets to make our autocomplete work:
1. Movie Titles List
Let's keep track of a sorted set called movies. Think of this like a dictionary that helps us find movies quickly. When someone types "int", we can instantly find all movies that start with those letters.
The first occurrence of "int" will be found by ZRANK and then starting from that position the full movie names with wild card INT*$* will be fetched.
2. Popular Movies List
Let's also keep track of a sorted set called movie-popularity. This is our "trending movies" list.
Every time someone clicks on a movie in the search results, that movie gets more popular by incrementing its score using ZINCRBY. The most clicked movies show up first in future searches.
It's like how Netflix shows you trending movies - the more people watch something, the higher it appears in recommendations.
In our case, after finding out the exact matches for INT*$*, we go and check their scores at movie-popularity to get the most popular ones.
The Algorithmic Flow
graph TD
A[User types 'int'] --> B[ZRANK: Find lexicographic position of 'INT']
B --> C[ZSCAN: Retrieve matches starting from position (movies set)]
C --> D[Filter: Extract complete terms containing '$']
D --> E[ZMSCORE: Get popularity scores for all matches (movie-popularity set)]
E --> F[Rank: Return highest-scored suggestion]
G[User selects suggestion] --> H[ZINCRBY: Increment popularity score]
H --> I[Future searches: Higher scored items rank first]
I --> AAs users search and click on suggestions, the system learns and improves. The more people use it, the better it gets at showing the most relevant suggestions first.
Let's Build the Autocomplete System
Let's look at how we build this autocomplete system step by step. We'll keep it super simple!
Step 1: Adding Movie Titles to Redis
First, we need to add our movie titles to Redis so we can search them later. You can start with a simple list of movies from anywhere - maybe your database or just a text file. Here's how we add them:
import { Redis } from "@upstash/redis";
const redis = new Redis({
url: process.env.UPSTASH_REDIS_URL!,
token: process.env.UPSTASH_REDIS_TOKEN!,
});
// Example: your list of titles
const titles = [
"Interceptor",
"Interstate 60",
"Interstellar",
// ... more titles
];
async function populateAutocomplete() {
// Insert prefixes and full titles into the 'movies' sorted set
for (const title of titles) {
let term = title.toUpperCase();
let terms = [];
for (let i = 1; i < term.length; i++) {
terms.push({ score: 0, member: term.substring(0, i) });
}
terms.push({ score: 0, member: term });
terms.push({ score: 0, member: term + "$" + title });
await redis.zadd("movies", ...terms);
}
// Insert all titles into the 'movie-popularity' sorted set for popularity tracking
await redis.zadd(
"movie-popularity",
...titles.map((title) => ({
score: 0,
member: title.toUpperCase(),
})),
);
}
populateAutocomplete();Let's break down what the code above does:
-
For each movie title, we store:
- All possible partial matches (like "INT", "INTE", "INTER" for "Interstellar")
- The complete title itself
- A formatted version for display
-
We also create a separate list that tracks how popular each movie is, starting at zero views
This gives us everything we need to show smart suggestions as users type and learn from what they click.
Step 2: Finding the Best Matches
Next, we'll look at how we search through these movie titles to find matches. Our matchQuery function does all the heavy lifting:
export const matchQuery = async (query: string): Promise<string | null> => {
const upperQuery = query.toUpperCase();
// Step 1: Find starting position using lexicographic ordering
let rank = await redis.zrank("movies", upperQuery);
if (rank === null) return null;
// Step 2: Efficiently scan for matches from that position
const scanResult = await redis.zscan("movies", rank, {
match: `${upperQuery}*$*`,
count: 1000,
});
// Step 3: Extract complete entries and get their popularity scores
const completeTitles = scanResult[1].filter(
(el, idx) => idx % 2 === 0 && el.includes("$"),
);
const baseNames = completeTitles.map((title) => title.split("$")[0]);
const scores = await redis.zmscore("movie-popularity", baseNames);
// Step 4: Return the highest-scored (most popular) match
const maxScore = Math.max(...scores);
const bestMatchIndex = scores.indexOf(maxScore);
return completeTitles[bestMatchIndex].split("$")[1];
};Learning from User Choices
When someone selects a movie title, we add 1 point to its score. Movies with more points show up higher in the suggestions list. It's that simple!
The system gets smarter over time by keeping track of what people actually choose.
const onSubmit = async (title: string) => {
// Handle submit logic here
await redis.zincrby("movie-popularity", 1, title.toUpperCase());
};How Fast Is It?
Let's look at how fast this solution is by breaking down the time each operation takes:
- ZRANK: O(log N) - Logarithmic lookup time
- ZSCAN: O(log N + M) - Where M is the number of returned elements
- ZMSCORE: O(N) - Where N is the number of matched results, not the total dataset size
- ZINCRBY: O(log N) - Atomic increment with logarithmic complexity
As we add more movie titles, the performance stays consistent.
Conclusion: What We Built Together
You've just learned how to build a smart search box that gets better over time without any AI!
Our autocomplete learns from what people choose and uses that information to show better suggestions.
It's fast, simple, and becomes more helpful the more people use it.
Want to talk about Redis optimization strategies or share your own implementations? Join us on Discord!