How We Indexed 45M Hacker News Posts with Upstash Redis Search

hackernewstrends.com is a tool that shows how often Hacker News talked about a term over time, similar to Google Trends. You can follow a single term, or put two of them head to head, like OpenAI vs Anthropic or MySQL vs Postgres.
We built it by storing 45M posts and comments in a single Upstash Redis database, and using Upstash Redis Search to power both the trend lines and the full-text search box.
This post is a walkthrough of how it works: creating the index, drawing the trend lines, and how we query and rank the results. You can check the source at upstash/hacker-trends.
Ingesting the data
This is the simple part. We take the monthly Parquet dumps from the Hacker News dataset on Google BigQuery and load them into Redis with a small script that runs daily in GitHub Actions.
Each post and comment is stored as a hash. Nothing special here, just a plain HSET:
await redis.hset(`hn:${item.id}`, {
title: item.title, // headline (empty for comments)
text: item.text, // body (comments + Ask HN), HTML stripped
by: item.by, // author handle
type: typeName, // story | comment | poll | job
time: isoTimestamp, // ISO 8601
score: item.score, // upvotes (0 for comments)
ndesc: item.descendants, // comment count
});The keys go in over the REST API, so the same script works from a GitHub Action, a serverless function, or your laptop, with no connection to keep alive.
Creating the index
To use Upstash Redis Search, you create an index with a schema. You also give it a key prefix, so it knows which keys to index (in our case everything under hn:*). Once the index exists, every hash you write under that prefix gets indexed automatically.
import { Redis, s } from "@upstash/redis";
const redis = Redis.fromEnv();
const schema = s.object({
title: s.string(),
text: s.string(),
by: s.keyword(),
type: s.keyword(),
time: s.date().fast(),
score: s.number("F64"),
ndesc: s.number("F64"),
});
const index = await redis.search.createIndex({
name: "hn",
dataType: "hash",
prefix: "hn:",
schema,
});The schema field types are simple:
s.string()is full-text search. The text gets split into words (tokenized) so you can match any word inside it.s.keyword()is exact-match only, no tokenization. Good for short values you filter or group on, like the author handle or the post type. For example, grouping bybygives you the top authors who mentioned a term.s.number("F64")is a numeric field. Use it for ranking and for range filters.s.date().fast()is an ISO date. The.fast()makes it sortable and usable inside a date histogram, which is exactly what the trend line needs.
You can see the full list of field types in the schema definition docs.
Building the trend lines
Trend lines are a simple aggregate query: How many posts and comments mentioned this term per month?
We run a SEARCH.AGGREGATE with a date histogram over the time field, bucketed every 30 days. Redis groups the matching documents into monthly buckets and counts each one.
const { by_month } = await index.aggregate({
filter: { title: { $eq: "rust" } },
aggregations: {
by_month: {
$dateHistogram: { field: "time", fixedInterval: "30d" },
},
},
});
// by_month.buckets -> [{ key, keyAsString, docCount }, ...]Every bucket has a key (the month) and a docCount (how many posts and comments matched). Plot docCount over key and you have the line. This runs live on every search, there is no precomputed table and no separate analytics pipeline next to Redis. This is also why the time field is marked .fast() in the schema: a date histogram needs it.
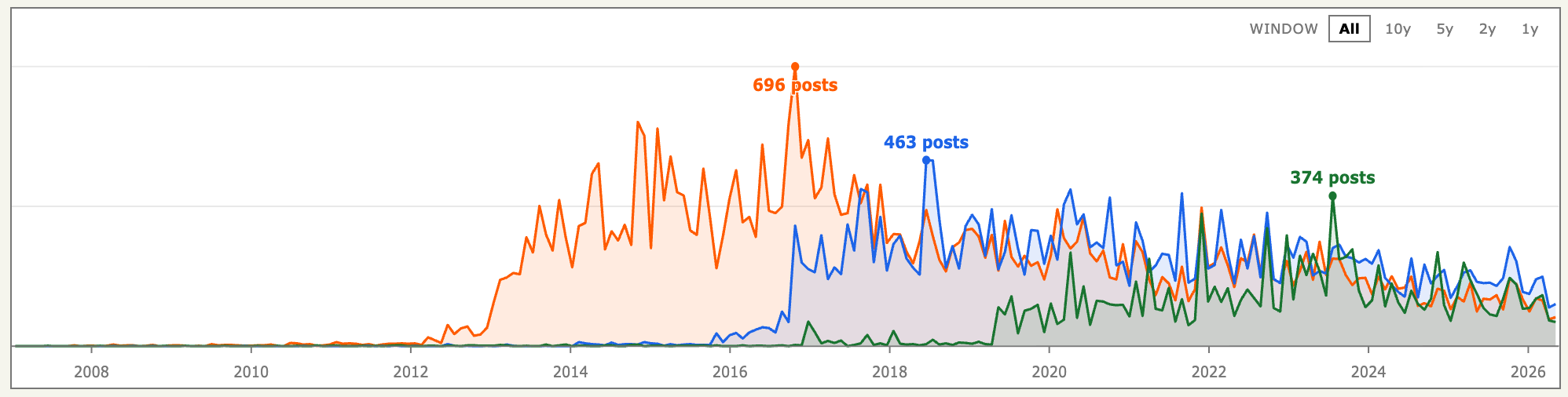
Querying the data
Querying is just as straightforward. We already created the index, so to query it we just grab a handle to it by name:
import { Redis, s } from "@upstash/redis";
const redis = Redis.fromEnv();
const index = redis.search.index({ name: "hn", schema });
const results = await index.query({
filter: { title: { $eq: "rust" } },
});Each result comes back as { key, score, data }. The data field is fully type-safe, its shape is inferred straight from the schema you passed in, so you get autocomplete and type errors on every field.
You will notice we write $eq everywhere. By default, a bare string like title: "rust" uses smart matching: it mixes phrase, prefix, and fuzzy matching, which is great for a typo-tolerant search box. But this is a trends tool, so we want an honest count of real mentions, not a fuzzy neighborhood. $eq still matches the whole word "rust" anywhere in the title, just without the fuzzy expansion. The full list of operators is in the querying docs.
A mention can be in the title or the body, so we match either one with an $or:
const results = await index.query({
filter: {
$or: [
{ title: { $eq: "rust" } },
{ text: { $eq: "rust" } },
],
},
});We also want to limit the results to a date range and cap how many come back, so we wrap the term match in an $and next to a time range, and pass a limit:
const results = await index.query({
filter: {
$and: [
{ $or: [
{ title: { $eq: "rust" } },
{ text: { $eq: "rust" } },
]},
{ time: { $gte: "2024-08-01", $lt: "2024-09-01" } },
],
},
limit: 30,
});Ordering by relevance
Ordering is a big part of any search engine. We want posts ranked by a score that combines three things:
- the full-text match (BM25)
- the number of upvotes
- the number of comments
We use a log-based scoring function so that a 1000-upvote story is not ~100x a 10-upvote one, and a quietly good post is not buried. So the score becomes:
score = BM25 + 50 * log(1 + upvotes) + 30 * log(1 + comments)
Upstash Redis Search lets you define exactly that with a custom scoring function:
const results = await index.query({
filter,
scoreFunc: {
fields: [
{ field: "score", modifier: "log1p", factor: 50 },
{ field: "ndesc", modifier: "log1p", factor: 30 },
],
combineMode: "sum",
scoreMode: "sum",
},
});This blends the text match with the popularity of the post, so the genuinely discussed threads rise to the top. Without it, plain BM25 ranks five different posts literally titled "Bitcoin" (with one or two upvotes each) above the ones people actually argued about. You can read more about scoring in the querying docs.
scoreFunc and orderBy are mutually exclusive: one ranks by a computed relevance score, the other sorts by a raw field. So when a user sorts by points, comments, or recency, we drop the score function and pass an orderBy instead.
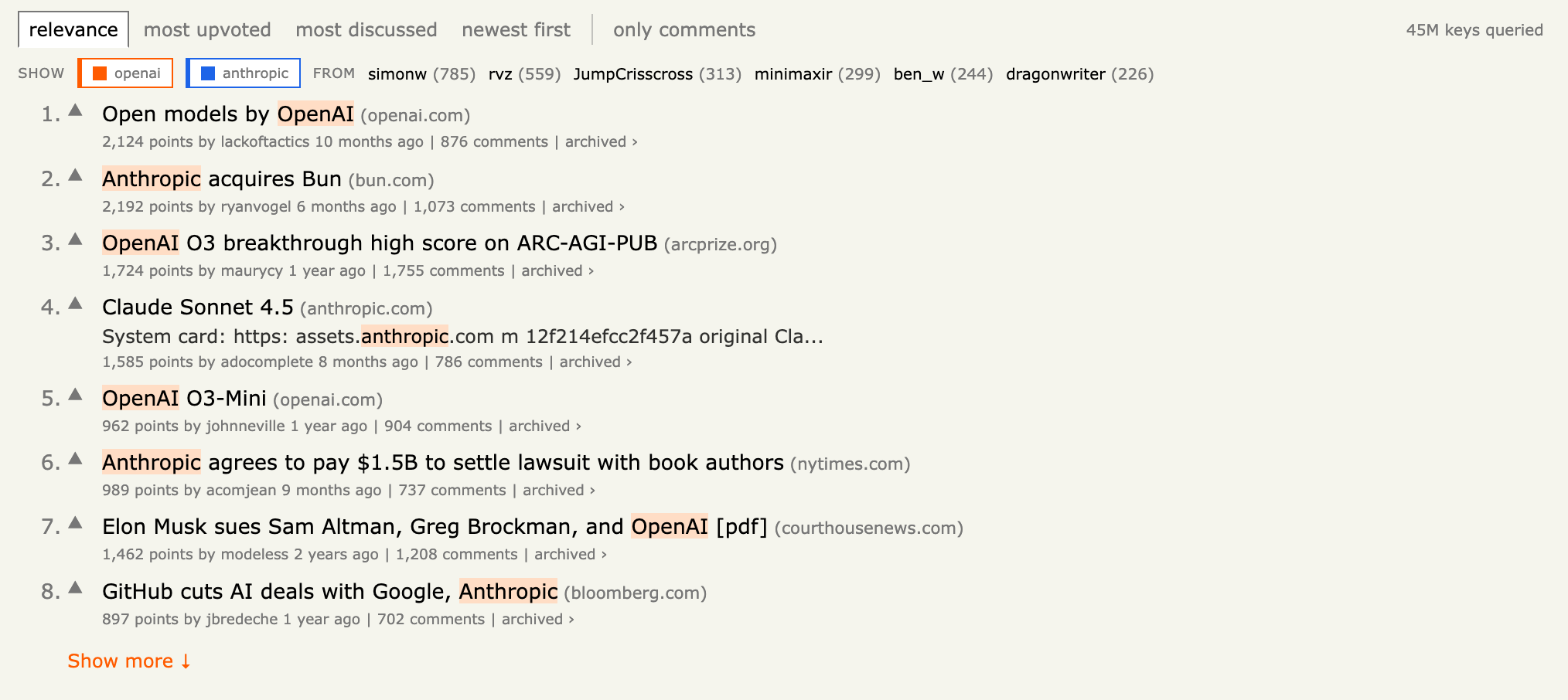
Bonus: boost inside the query
Say we want a match in the title to count for more than a match in the text. We can do that by boosting the title clause right inside the query:
const results = await index.query({
filter: {
$or: [
{ title: { $eq: "rust", $boost: 5.0 } },
{ text: { $eq: "rust" } },
],
},
});Now a headline mention outranks a body mention, which gives more relevant results. With just a few lines you get a search experience that would normally take a separate search cluster to build.
It runs at the edge, worldwide
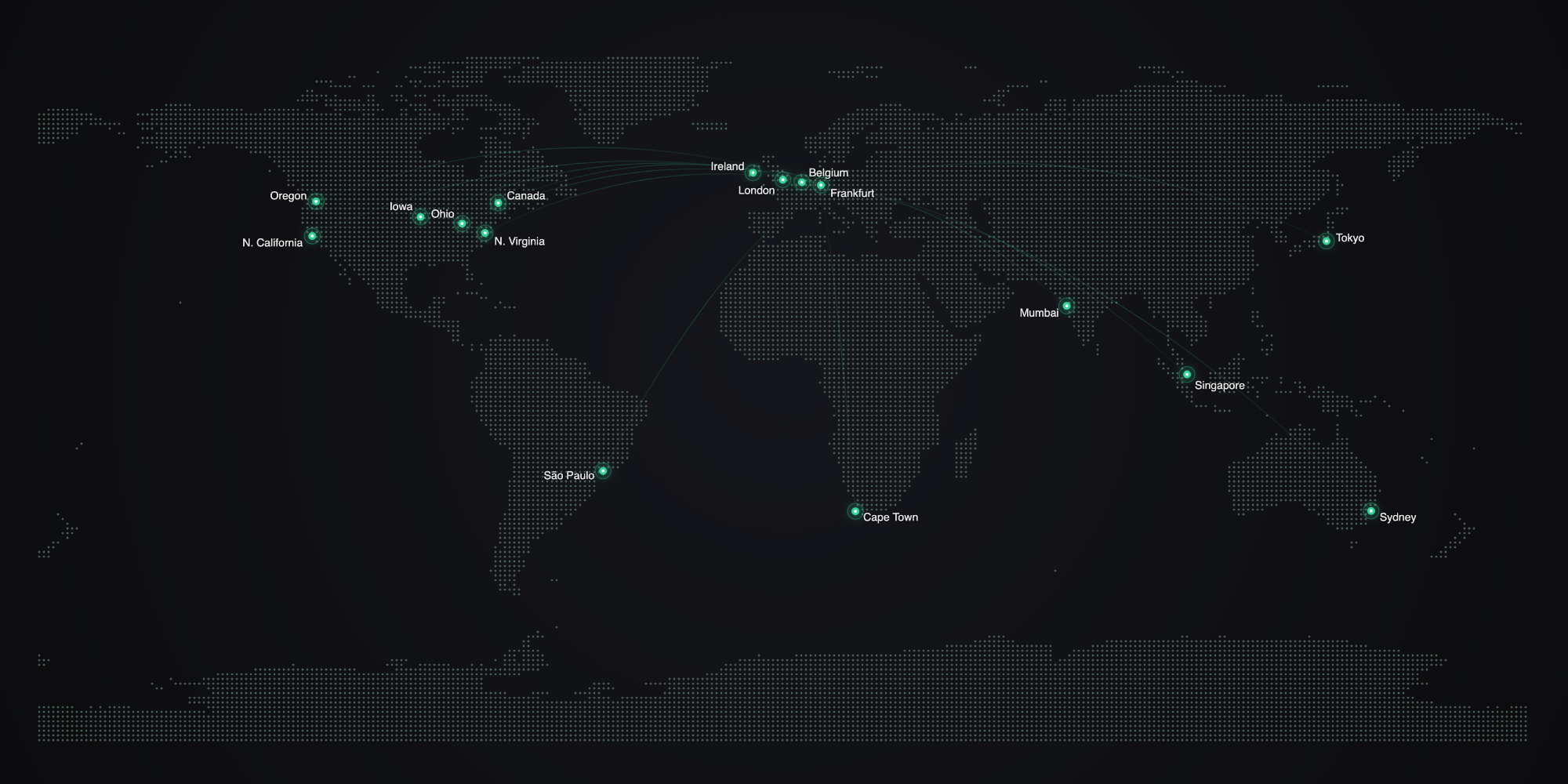
Upstash Redis runs in 20+ regions around the world. By adding read regions to your database, your search and aggregate queries get served from the region closest to each user, so the same query stays fast whether it is fired from Frankfurt or São Paulo. You get a global search engine without running any infrastructure of your own.
Conclusion
That is the whole thing: 45M posts and comments, stored as plain hashes, full-text matched and bucketed into a monthly trend line in a few milliseconds, with no separate search cluster and no analytics pipeline beside it.
The code is all open source at upstash/hacker-trends, including the ingest script, the schema, and the shared query builder that both the search and the trend chart run through.
If you want to build something similar, start with the Upstash Redis Search introduction, then the querying and aggregations docs cover everything used in this post. And go play with hackernewstrends.com to see it running.