Context7 vs Claude Code's Web Search: A Token and Cost Benchmark


Introduction
Context7 is a tool that searches and injects relevant, version-aware documentation directly into your coding agent's context at query time. Rather than relying on general web search, Context7 is purpose-built for documentation retrieval — bringing the right docs to your agent so it can generate accurate, grounded code.
Context7 delivers value across five dimensions:
-
Zero Hallucinations. Context7 supplies fresh, version-accurate docs at query time, so agents generate code from correct sources — not stale or deprecated APIs that web search might surface.
-
Fewer Tokens, Faster Responses. Context7 returns focused documentation slices instead of large page-level artifacts, cutting token waste, cost, and latency.
-
Safe by Default. Web search exposes agents to the open internet, where malicious or prompt-injected content can influence code generation. Context7's injection detection and trust scoring keep unsafe content out.
-
Governed Context. Add private repos, wikis, and PDFs as sources. Control what the agent sees, monitor usage, and enforce standards.
-
Developer Productivity. The agent fetches the right docs automatically — fewer Slack threads, wikis, and browser tabs, more shipping.
As coding agents increasingly adopt internal web search tools, users often ask where Context7 fits. While web search can retrieve documentation, it is not always efficient: results can be outdated, unsafe, or bloated with irrelevant page content — adding unnecessary tokens to the agent's context and increasing cost. In this blog post, we compare the token and financial costs of Claude Code's internal WebSearch/WebFetch tools against Context7. We also have a separate blog post that covers the fundamental differences between Context7 and general web search.
Experiment Design
We tested five categories of challenging documentation queries to compare Claude Code's internal web search and fetch tools with Context7. These categories are:
- Evolving libraries: How do I use extended thinking with opus 4.7?
- Niche libraries: Where can I configure function schedules in Notte?
- Queries that reference multiple libraries: In the latest playwright and testing library docs, how do their approaches to locating elements by accessible role differ?
- Popular or frequently used libraries: How do claude code memory files work, and how can it be viewed or edited?
- Queries that do not have a specified library: How do relations(), one(), and many() define relationships separately from table schemas?
A link to the repo with all the queries used can be found here.
We chose these categories to test different retrieval stressors. Evolving libraries test whether a tool can isolate current information when APIs and documentation are frequently updated. Niche libraries test retrieval for lesser-known companies or products with a smaller web presence; many of the queries were based on recent YC companies. Multiple-library queries test how well each approach handles retrieval across more than one documentation source. Popular libraries test retrieval in noisy environments where there is a large amount of documentation, blog content, tutorials, and third-party material. Finally, unspecified-library queries test whether the tool can infer the relevant library from API names and keywords.
Each category contains 20 queries for a fair comparison. The experiment was conducted using the Claude Code Agent SDK. For the same set of questions, the SDK was run with either Context7 tools or Claude Code's internal WebSearch and WebFetch tools. The following prompts were appended to each query:
Use web search. Use web fetch when needed.Use Context7.
All questions in a category were run one after another. A 5-minute sleep was added between running Context7 and Web Search to mitigate prompt caching effects.
We ran the experiments using Anthropic's model defaults: Claude Opus 4.7 for the main agent and Claude Haiku 4.5 for auxiliary tasks.
Results
We report results for each category using token counts broken down by type.
Input tokens are new tokens that Claude has to read and process that are not already cached. This includes the user's query, tool call results, and tool definitions. Output tokens are the tokens Claude generates, including the final response, reasoning, and tool call invocations.
Cost figures are taken directly from the Claude console and reflect what was reported at the time of each run.
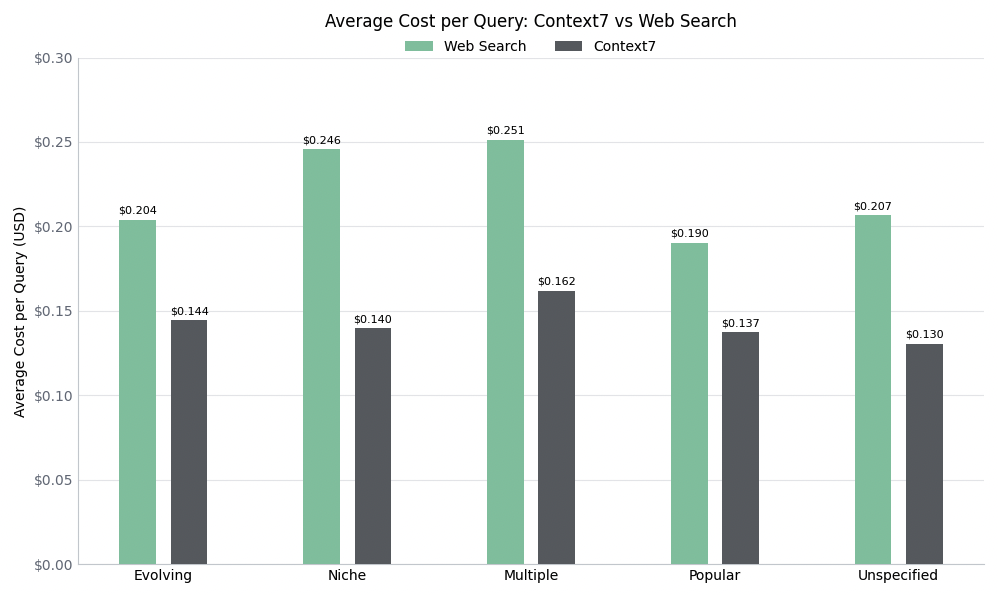
Context7 reduction vs. Web Search:
| Category | Cost Reduction | Input Token Reduction | Output Token Reduction | Total Token Reduction | Tool Count Reduction |
|---|---|---|---|---|---|
| Evolving | 29.24% | 99.01% | 50.81% | 27.12% | 13.79% |
| Niche | 43.12% | 99.12% | 61.95% | 50.19% | 55.88% |
| Multiple | 35.60% | 99.03% | 49.80% | 41.51% | 8.75% |
| Popular | 27.89% | 98.70% | 49.87% | 21.70% | 6.12% |
| Unspecified | 36.94% | 99.02% | 52.43% | 43.52% | 29.31% |
| Avg | 34.56% | 98.98% | 52.97% | 36.81% | 22.77% |
Web Search:
| Category | Cost | Input Tokens | Output Tokens | Cache Write | Cache Read | Total Tokens | Tool Count |
|---|---|---|---|---|---|---|---|
| Evolving | $0.20 | 37903.55 | 3015.55 | 9960.35 | 73298.20 | 124177.65 | 2.90 |
| Niche | $0.25 | 42018.85 | 3528.15 | 11429.45 | 110960.15 | 167936.60 | 5.10 |
| Multiple | $0.25 | 45305.45 | 4036.00 | 12245.40 | 80140.90 | 141727.75 | 4.00 |
| Popular | $0.19 | 28840.60 | 2945.40 | 10183.20 | 66784.70 | 108753.90 | 2.45 |
| Unspecified | $0.21 | 37945.75 | 2924.55 | 9611.40 | 89732.90 | 140214.60 | 2.90 |
| Avg | $0.22 | 38402.84 | 3289.93 | 10685.96 | 84183.37 | 136562.10 | 3.47 |
Context7:
| Category | Cost | Input Tokens | Output Tokens | Cache Write | Cache Read | Total Tokens | Tool Count |
|---|---|---|---|---|---|---|---|
| Evolving | $0.14 | 374.05 | 1483.40 | 10922.00 | 77726.10 | 90505.55 | 2.50 |
| Niche | $0.14 | 371.20 | 1342.50 | 11324.90 | 70607.40 | 83646.00 | 2.25 |
| Multiple | $0.16 | 440.95 | 2025.90 | 12259.55 | 68166.70 | 82893.10 | 3.65 |
| Popular | $0.14 | 375.60 | 1476.50 | 10185.45 | 73117.10 | 85154.65 | 2.30 |
| Unspecified | $0.13 | 371.70 | 1391.10 | 9865.80 | 67563.10 | 79191.70 | 2.05 |
| Avg | $0.14 | 386.70 | 1543.88 | 10911.54 | 71436.08 | 84278.20 | 2.55 |
On average, Context7 reduced cost by 34.56% and total token usage by 36.81%. The largest gains appeared in niche libraries, unspecified-library queries, and queries that referenced multiple libraries.
The most consistent pattern is the reduction in input tokens. Across every category, Context7 reduced input tokens by roughly 99%. WebSearch and WebFetch likely return larger page-level artifacts that are added directly to the agent's context. Context7, by contrast, returns more condensed documentation context, reducing the amount of text the model has to process.
This reduction also affects output tokens. When the model receives less noisy or irrelevant context, it has less material to filter, reconcile, and reason over. As a result, Context7 also reduced output tokens by an average of 52.97%.
The category-level results show where these savings are most pronounced. Context7 delivered its strongest performance on niche-library queries. In these cases, Web Search had to work harder to locate the correct source in a lower-signal web environment, resulting in a higher average number of tool calls. By contrast, Context7 was able to retrieve relevant documentation with fewer tool calls and fewer tokens.
The second best performing category was queries with an unspecified library. API names, function names, and other keywords served as clues that helped Context7 identify the relevant documentation source. Web Search was also able to infer the same target, but it typically required more exploratory retrieval through additional tool calls, similar to the niche-library category.
The third best performing category for Context7 was queries involving multiple libraries. The main challenge in this category was gathering context from more than one documentation source. Context7's tool call count was slightly higher here than in the other categories, but its token usage remained low because each retrieval returned a compact documentation slice. Its tool call count was also still lower than Web Search's.
Context7's improvement in the evolving-library category was smaller than the other categories, but it still outperformed Web Search. This advantage likely comes from Context7's ability to retrieve more focused documentation context, organized by version and source. This structure keeps retrieval targeted and reduces noise when searching for the correct documentation source and slice.
For popular libraries, Context7 showed the smallest improvement, with a 27.89% cost reduction and a 21.70% total token reduction. This is expected because popular libraries are easier for web search tools to find. Even in this favorable case for Web Search, Context7 still reduced cost and token usage by keeping the retrieved context focused on technical documentation and in a more condensed format.
Conclusion
Across all five categories, Context7 reduced total token usage by 36.81% and cost by 34.56%. The gap between token reduction and cost reduction reflects how Web Search uses Claude's built-in cost mitigations: aggressive prompt caching keeps repeated context cheap, and auxiliary tool calls are handled by Claude Haiku 4.5 rather than the more expensive Opus model. These mechanisms partially offset the higher token volume, which is why a 99% reduction in input tokens does not translate to a proportional reduction in cost. The largest driver was input tokens, which dropped by roughly 99% across every category. This suggests that web-based retrieval often adds large page-level outputs to the prompt, while Context7 returns a smaller, more focused documentation slice.
The smaller context also reduced output tokens by 52.97% on average, likely because the agent had less irrelevant material to filter. For documentation-heavy tasks, Context7 keeps retrieval more bounded and cost-efficient than general Web Search.
Token and cost efficiency gains are only meaningful if retrieval quality holds. In practice, Context7's focused documentation retrieval produces better answers with fewer hallucinations — the savings come from returning less noise, not less signal. Context7 also filters out malicious and prompt-injected content that open web search can introduce into agent context. We are preparing a separate benchmark covering answer quality and safety, which will quantify these advantages directly.
Takeaways
- Context7 reduced cost across every category tested
- On average, Context7 used 36.81% fewer tokens and cost 34.56% less than Web Search
- The largest driver of savings was the ~99% reduction in fresh input tokens — web search returns large page-level artifacts, Context7 returns focused documentation slices
- Cost savings are partially moderated by Web Search's use of caching and Haiku for auxiliary calls, but Context7 still wins on every category
- Beyond efficiency, Context7 produces better answers with fewer hallucinations and filters out malicious content — advantages that will be quantified in a forthcoming benchmark
Appendix: Benchmark Details
The full set of queries used in each category, along with the per-query results for both Web Search and Context7, is available in the benchmark repo.