Why Web Search Fails AI Agents (and What Context7 Fixes)

Large language models are fundamentally constrained by their training data. In practice, that means a fixed knowledge cutoff, where newer APIs, version changes, and evolving documentation are out of reach. When generating code, this limitation shows up in predictable ways: outdated references, subtle version mismatches, and, in the worst cases, confident hallucinations.
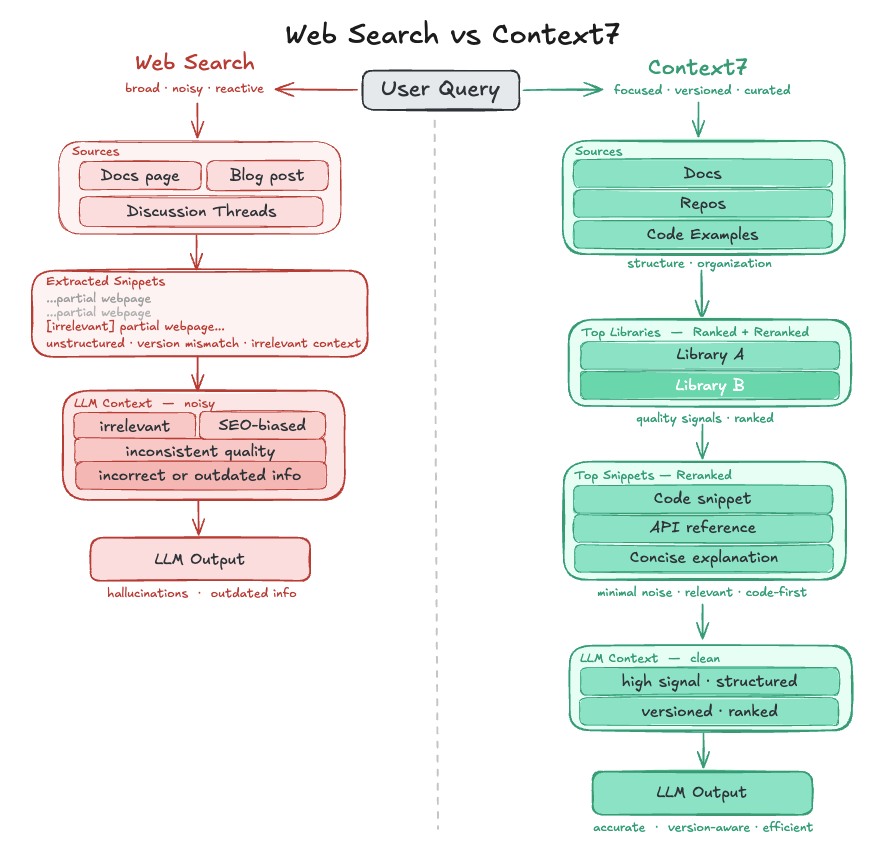
To address this, many AI agents rely on web search tools to retrieve up-to-date information at query time. While this helps fill in the gaps, it introduces a new set of problems: unstructured data, inconsistent quality, and inefficient retrieval that often requires multiple passes to assemble a usable answer.
Context7 takes a different approach. It scopes to authoritative documentation and uses a lightweight, structured retrieval process with reranking and version awareness, ensuring that the results are precise and consistent.
In this post, we compare Context7 to standard web search-based retrieval, using Cursor as a baseline, across key dimensions: token and time efficiency, relevance, version handling, safety, and customization.
Token Efficiency
One of the less obvious limitations of web search in AI agents is how tokens are allocated during retrieval. While modern tools can extract and prioritize relevant parts of a webpage, the underlying content is still organized as full documents rather than small, query-specific units. As a result, even filtered excerpts often include surrounding context or only partially answer the question.
Context7 decouples retrieval from document structure, allowing information to be recomposed based on the query rather than constrained by page boundaries. Instead of retrieving sections from a small number of pages, it returns targeted snippets compiled from across the documentation. This allows related details to be surfaced together despite their location in the documentation. These snippets are also carefully extracted to condense information into high-signal, query-relevant units, selected based on factors such as the presence of unique information or code examples.
Here is an example of a snippet returned by Cursor's web search tool, illustrating how retrieved content is shaped by full-page document structure rather than the query itself:
#### 3. Unified encoding API
The `encode_plus` method is deprecated in favor of the single `__call__` method.
#### 4. `apply_chat_template` returns `BatchEncoding`
Previously, `apply_chat_template` returned `input_ids` for backward compatibility. Starting with v5, it now consistently returns a `BatchEncoding` dict like other tokenizer methods.
# v5
messages = [
{"role": "user", "content": "Hello!"},
{"role": "assistant", "content": "Hi there!"}
]
# Now returns BatchEncoding with input_ids, attention_mask, etc.
outputs = tokenizer.apply_chat_template(messages, return_tensors="pt")
print(outputs.keys()) # dict_keys(['input_ids', 'attention_mask'])
vs. Context7:
### Apply chat template returning BatchEncoding
Source: https://github.com/huggingface/transformers/blob/v5.0.0/MIGRATION_GUIDE_V5.md
Use apply_chat_template method which now returns a BatchEncoding dictionary containing input_ids, attention_mask, and other tokenizer outputs. Previously returned only input_ids for backward compatibility. Provides consistent return type with other tokenizer methods.
messages = [
{"role": "user", "content": "Hello!"},
{"role": "assistant", "content": "Hi there!"}
]
outputs = tokenizer.apply_chat_template(messages, return_tensors="pt")
print(outputs.keys()) # dict_keys(['input_ids', 'attention_mask'])Time Efficiency
Another key difference between Context7 and search-based approaches is how retrieval accesses information.
Web search tools often require multiple passes of retrieving and interpreting information to arrive at a complete answer. Context7’s condensed corpus reduces the need for these repeated actions while still getting the same answer.
Context7 achieves this through a structured, two-step retrieval process. First, it surfaces relevant libraries (documentation sources) for the agent to choose from. These libraries are scoped and versioned, which dramatically narrows the search space for a given query. Instead of searching across all available sources, the agent selects from a targeted subset that is likely to contain the desired information. Once a library is selected, Context7 retrieves documentation directly from that source.
Relevance and Accuracy
Web search results are often influenced by keyword matching and SEO signals. As a result, they may include content from blog posts and other less reliable sources rather than authoritative documentation.

In this example, Cursor’s web search tool generates multiple queries, including ones explicitly targeting sources like “Reddit” and other discussion-driven content. The retrieved pages are primarily blog posts, which the agent then uses to inform its answer. While these sources can be helpful, they are often incomplete, opinionated, or outdated.
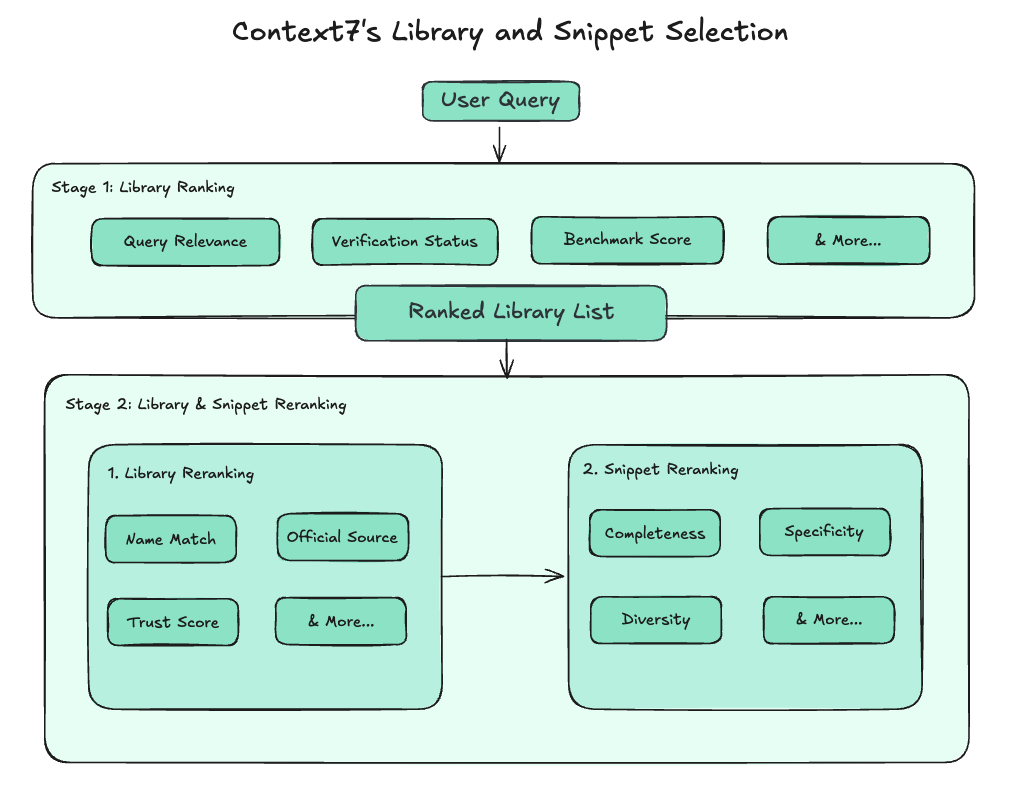
Context7 prioritizes primary sources such as official documentation websites and repositories, operating over a curated set of sources that is more likely to contain accurate, up-to-date, and complete information. Context7 also benchmarks the quality of those sources by generating questions from the source content and using general information from web search to identify core concepts, use cases, and recent updates. These questions are then graded against the retrieved context to evaluate how well the documentation can answer them. These scores are used to inform which libraries are retrieved, while also helping identify gaps in documentation quality.
To ensure that only the most relevant and high-quality information is returned, Context7 applies multiple ranking stages. First, libraries are retrieved and ranked using search relevance and general quality signals. The top library candidates are then evaluated to choose the best library for the query. Within that library, snippet candidates are fetched and selected to form the final context.
Version mismatch
Context7 organizes sources by version, so when a user specifies one, it retrieves content associated with that exact release. In the case of repositories, this effectively means working with a snapshot of what the repo looked like at that point in time.
Web search does not provide this level of precision. It typically relies on keyword matching to identify relevant content, which can surface results that are similar but not tied to the exact version requested.
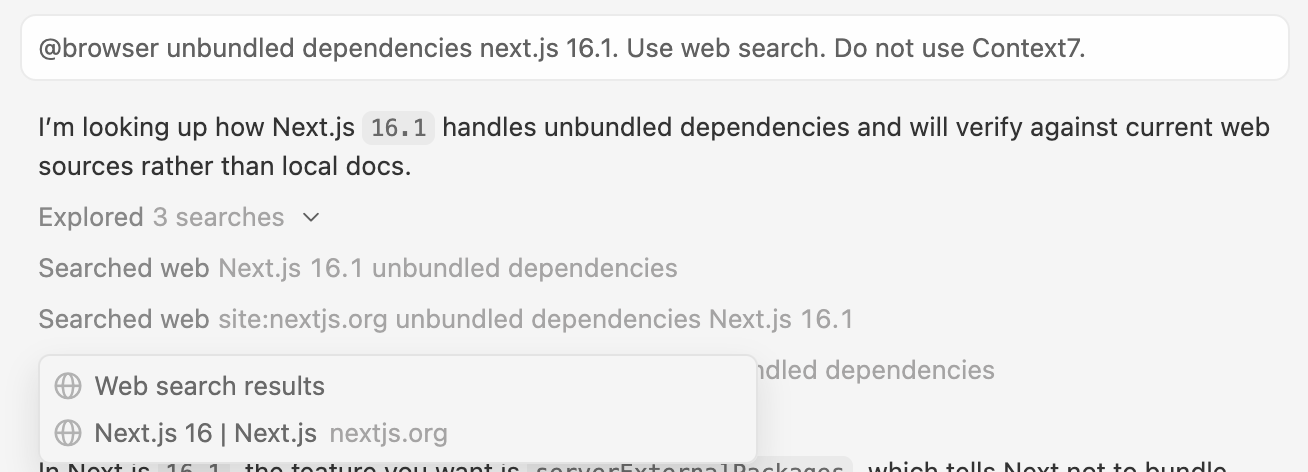
In this example, the query explicitly specifies Next.js 16.1, but the retrieved result corresponds to Next.js 16. The page web search retrieved doesn’t even contain the answer to the query.
In addition to maintaining versioned snapshots, Context7 uses a version analyzer that scans project content for signals that indicate previous versions may have been mixed with the current one. Web search, by contrast, typically relies on surface-level matching of search results rather than a deeper analysis of the content itself.
Safety and Security
Web search tools retrieve content from a wide range of sources, but how that content is filtered or evaluated for safety is not always explicit.
Context7 takes a proactive approach with built-in safeguards during ingestion and retrieval. Every submitted library is inspected at multiple stages of parsing using techniques such as pattern checks and classifiers to detect prompt injections, malware-like patterns, and other suspicious content.
In addition to filtering out problematic content before it is ever indexed, Context7 assigns a trust score to each library which penalizes suspicious sources and lowers their likelihood of being retrieved.
The result is a more controlled pipeline, where both ingestion and retrieval are designed to reduce the likelihood of unsafe or manipulated content reaching the model.
Content Moderation and Customization
Beyond improving retrieval quality, Context7 gives users direct control over how retrieval behaves, whereas web search offers little control.
One key capability is support for private repositories. Context7 can index private sources and include them during retrieval, whereas web search is limited to publicly available content. In addition, private repositories are prioritized, ensuring that relevant user-specific context is surfaced first.
Context7 also allows fine-grained control over what content is retrieved. This includes selecting the types of documentation to search from (such as repositories, websites, or llms.txt files), specifying exact libraries or organizations to include, and filtering by quality signals like verification status or trust score.
Context7 enables users to tailor results to their specific needs rather than relying on the defaults of a general-purpose system.
Conclusion
Context7 is frequently compared to web search tools, especially with the rapid improvements in LLMs and agents. However, neither newer LLMs nor web search tools fully solve the core issues that Context7 addresses:
- LLMs are limited by their training data → they are effectively snapshots of the internet at a specific point in time.
- Web search tools rely on broad, unstructured retrieval → while they surface up-to-date information, they introduce irrelevant context, version mismatch, and require multiple passes to assemble a usable answer.
Context7 bridges the gap between static model knowledge and noisy real-time retrieval by providing structured, curated, and version-aware context that is directly usable by the model.