Building a Fast, Typo-Tolerant AI Search Engine

Building a Fast, Typo-Tolerant AI Search Engine
Recently, I wanted to build a production search functionality for a tech stack I recently released called JStack. While researching how to build this, I realized that building search is usually a tradeoff between performance and quality of results.
The more time you have to search for relevant documents and re-rank them, the better the output - but at the expense of user experience.
The approach I took works exceptionally well for my use case of adding search to a documentation page, so I want to share it. For personal websites, small-to-medium product catalogues, and the like, this is my favorite way to implement search.
Intro
I built this search feature inside of a JStack application, a tech stack for building high-performance Next.js apps. That's why I'm using JStack for this post - but you can follow along just as easily using standard Next, Express, Hono, or anything else. How you connect to your backend is not important to follow along.
To create a new JStack app, use npx create-jstack-app@latest.
If we visualize the process of searching, it's really just these steps:
- Collect the user search query
- Send the query to our backend
- Retrieve relevant documents
- (Optional) Re-rank and weight documents
- Return and render documents on the frontend
1. Collect the User Search Query
Collecting the user input works with nothing more than standard React state. For good measure, we'll also implement debouncing to prevent sending a request to our backend on every keystroke. Instead, we're waiting until the user finishes typing their current thought before firing our backend request:
"use client";
import { useState } from "react";
import { useDebounce } from "../hooks/use-debounce";
export const SearchBar = () => {
const [searchTerm, setSearchTerm] = useState("");
const debouncedSearchTerm = useDebounce(searchTerm, 150);
return <>...</>;
};Our custom useDebounce hook is fairly simple, it looks like this:
import { useEffect, useState } from "react";
export function useDebounce<T>(value: T, delay: number = 500): T {
const [debouncedValue, setDebouncedValue] = useState<T>(value);
useEffect(() => {
const timer = setTimeout(() => {
setDebouncedValue(value);
}, delay);
return () => {
clearTimeout(timer);
};
}, [value, delay]);
return debouncedValue;
}Now, to actually set the state and collect user input, we'll keep the JSX minimal: a single input with space to render out the results below. This is not a guide on CSS. However, in production I've been using shadcn's Dialog component along with some custom styling that you can copy after this article.
"use client";
import { useState } from "react";
import { useDebounce } from "../hooks/use-debounce";
export const SearchBar = () => {
const [searchTerm, setSearchTerm] = useState("");
const debouncedSearchTerm = useDebounce(searchTerm, 150);
return (
<div className="mx-auto mt-20 flex w-full max-w-sm flex-col items-center justify-center">
<input
placeholder="Search..."
className="w-full rounded-lg border border-zinc-700 bg-zinc-800/70 px-4 py-2.5 text-zinc-100 placeholder-zinc-400 outline-none transition-all duration-200 focus:border-[#00e9a3] focus:ring-2 focus:ring-[#00e9a3]/50"
value={searchTerm}
onChange={(e) => setSearchTerm(e.target.value)}
/>
</div>
);
};2. Sending the Search Query to our Backend
The following code uses JStack to send data to our Next.js API. You can just as easily send a simple fetch request to any backend of your choice and pass the encoded search query as a query parameter.
To do this in JStack, we'll create a new search-router.ts to handle our search functionality:
import { z } from "zod";
import { j, publicProcedure } from "../jstack";
export const searchRouter = j.router({
byQuery: publicProcedure
.input(z.object({ query: z.string().min(1).max(1000) }))
.get(async ({ c, ctx, input }) => {
const { query } = input;
console.log("✅ Received query:", query);
return c.superjson([]);
}),
});This won't handle the actual retrieval of the answer yet, for now we're just checking to see if the request arrived successfully. All that's left to do is wire this router to our JStack's appRouter and we'll have a working API endpoint to call for the search:
import { InferRouterOutputs } from "jstack";
import { j } from "./jstack";
import { searchRouter } from "./routers/search-router";
const api = j
.router()
.basePath("/api")
.use(j.defaults.cors)
.onError(j.defaults.errorHandler);
const appRouter = j.mergeRouters(api, {
// ...
search: searchRouter,
});
export type AppRouter = typeof appRouter;
export type InferOutput = InferRouterOutputs<AppRouter>;
export default appRouter;Our endpoint is now available at http://localhost:3000/api/search/byQuery 🎉
Great. We have a working endpoint, ready to receive a user request. We also have an input to collect that user search request.
All that's left is to automatically pass the user request to our endpoint once the debounce threshold has passed. There's a really clever way to do this with react query - and that's to use the debounced search term as part of the query key.
The reason this is so clever is that while a user is typing, our query remains stale and retains its data. However, once the debounce is triggered and our debounced state is updated once, only then is the query automatically sent to our server to get the freshest data.
Implementing this is not rocket science, just be sure to use the debouncedSearchTerm as part of the query key:
"use client";
import { client } from "@/lib/client";
import { useQuery } from "@tanstack/react-query";
import { useRef, useState } from "react";
import { useDebounce } from "../hooks/use-debounce";
export const SearchBar = () => {
const [searchTerm, setSearchTerm] = useState("");
const debouncedSearchTerm = useDebounce(searchTerm, 150);
const prevResultsRef = useRef([]);
const { data: results, isRefetching } = useQuery({
queryKey: ["search", debouncedSearchTerm],
queryFn: async () => {
if (!debouncedSearchTerm) return [];
const res = await client.search.byQuery.$get({
query: debouncedSearchTerm,
});
const newResults = await res.json();
prevResultsRef.current = newResults;
return newResults;
},
initialData: [],
enabled: debouncedSearchTerm.length > 0,
placeholderData: () => prevResultsRef.current,
});
const displayedResults = isRefetching ? prevResultsRef.current : results;
return (
<div className="mx-auto mt-20 flex w-full max-w-sm flex-col items-center justify-center">
<input
placeholder="Search..."
className="w-full rounded-lg border border-zinc-700 bg-zinc-800/70 px-4 py-2.5 text-zinc-100 placeholder-zinc-400 outline-none transition-all duration-200 focus:border-[#00e9a3] focus:ring-2 focus:ring-[#00e9a3]/50"
value={searchTerm}
onChange={(e) => setSearchTerm(e.target.value)}
/>
</div>
);
};You may notice that we also keep track of previous results in a prevResultsRef. This is a small detail to maintain current results while a user requests new data. It's not really needed for the search to work, but it improves the user experience later on by preventing flickering during a query retry.
When we enter a query, we now see that a single request for our term is made to our backend (because of the debounce):
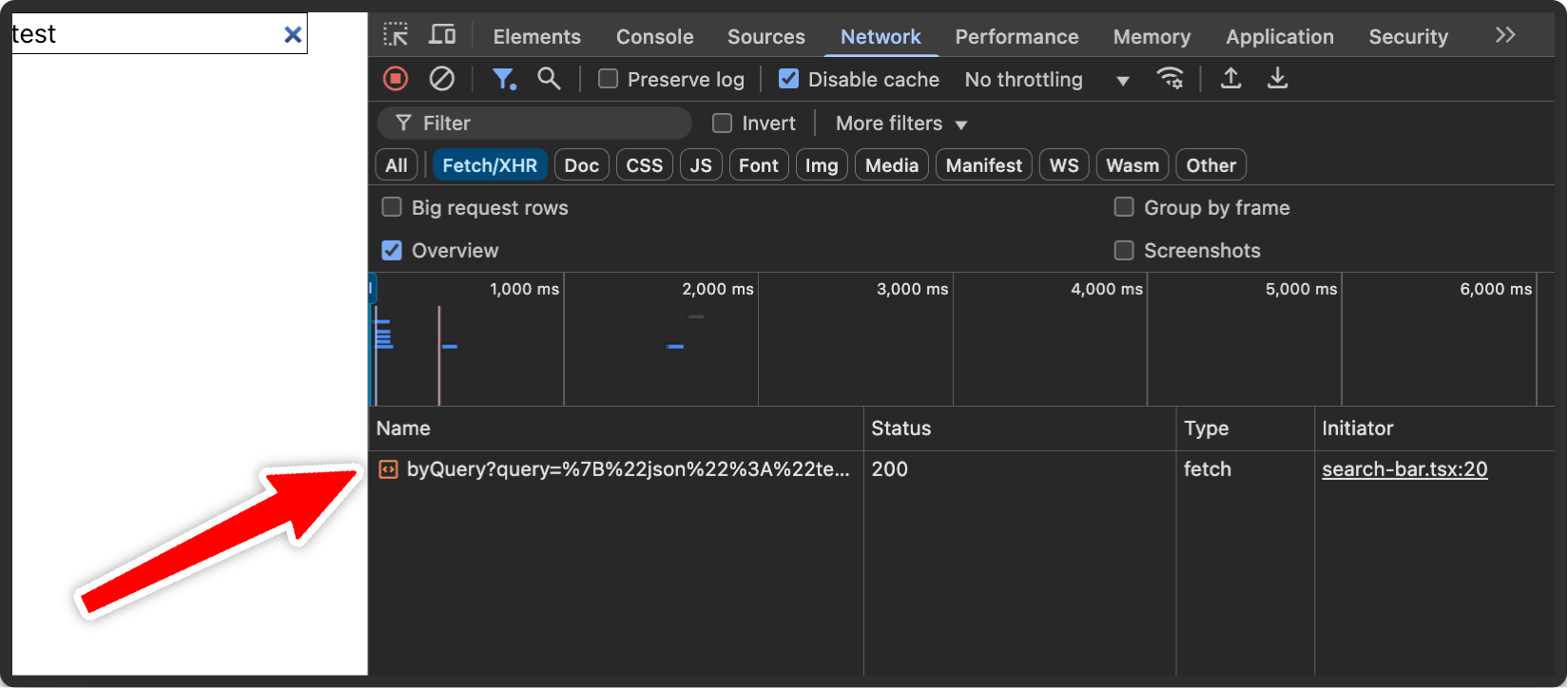
3. Retrieving Relevant Documents
Perfect! Everything is set up for us to actually retrieve relevant documents for the user's query. But wait...
...what documents are we actually searching?
The answer depends a lot on what kind of data you want to make searchable in your application. For the JStack documentation, we split all markdown files into their natural sections (separated by headings) to index each section separately:
I wrote a simple 70 line script that parses all documentation markdown files and extracts the following metadata:
- Root document title
- Section title
- Section text content
- Heading level (H1, H2, H3)
- Path to source file
This is all the information we need to display useful search results and a snippet of content for each section. Also, including both the section title and content snippets allows us to beautifully highlight matching search terms to make the results more intuitive to understand.
Example of results highlighting:
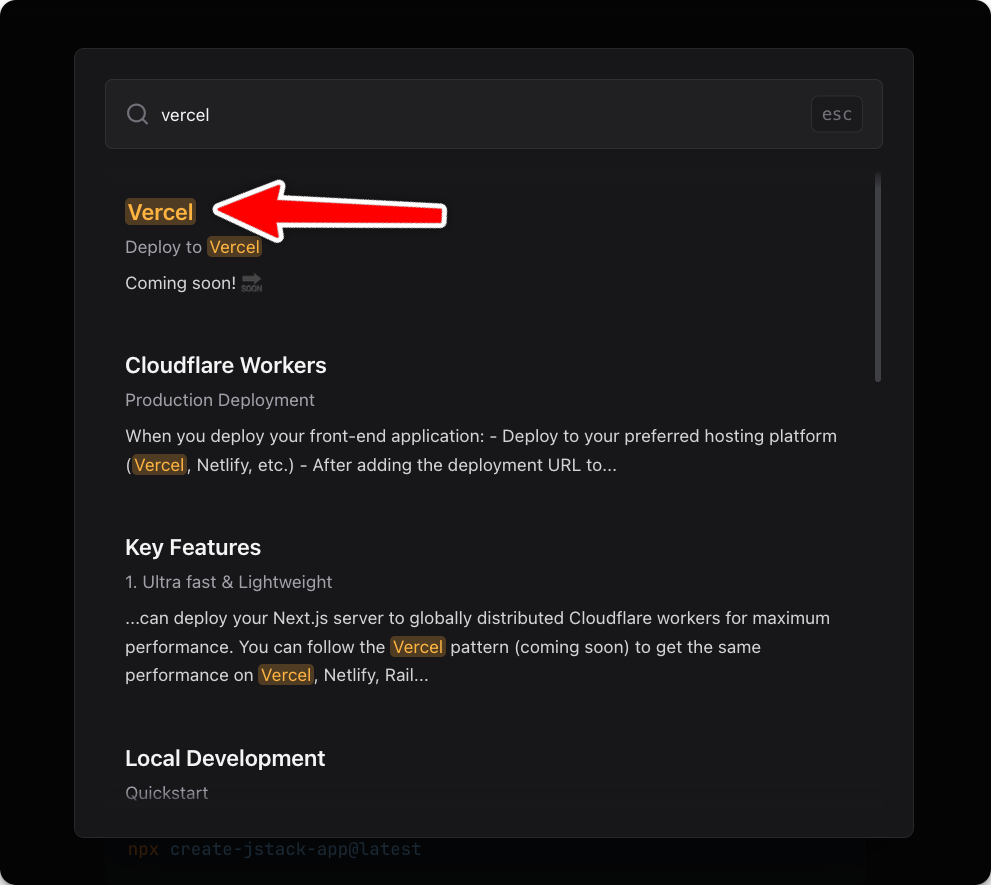
You can find the full script that converts the JStack markdown files to searchable vector entries in the open source JStack repository here.
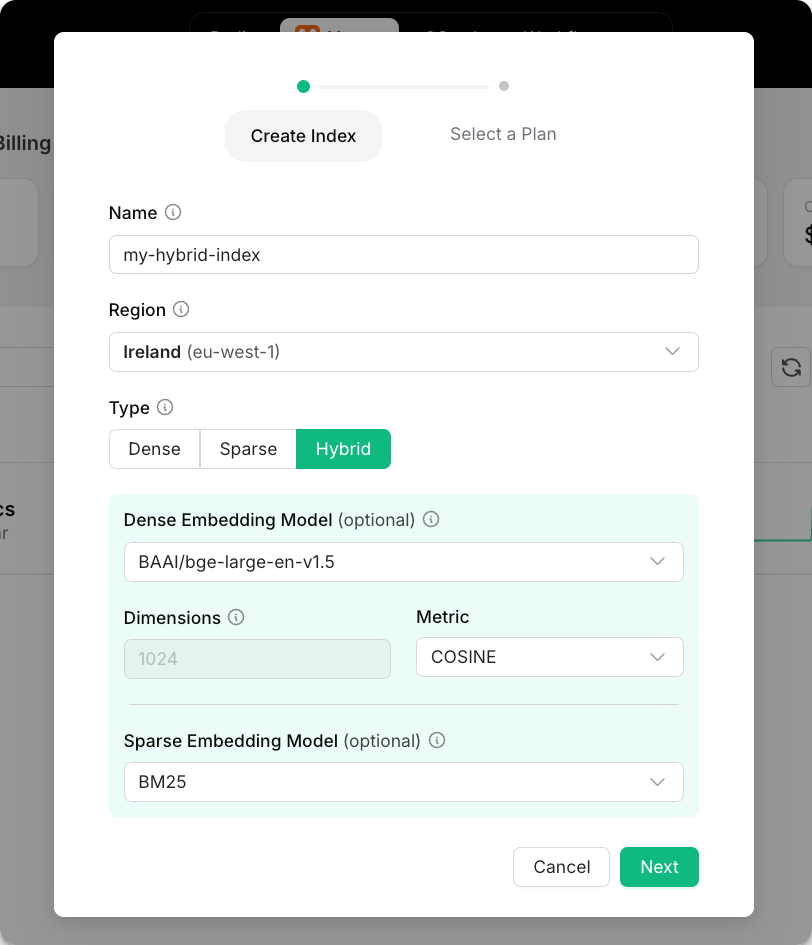
To have a place to store these vectors and make them searchable, I'm using an Upstash Vector Hybrid Index. A hybrid index automatically combines full-text and semantic search when a query is run against it. If you want to copy my exact settings, create your index with the following settings (they work very well for me)
After copying the index environment variables into our indexing script and running it, we'll see that our entire docs appear as searchable vectors in our Upstash vector database. In the case of JStack, that's 62 vectors, each representing a section of the docs:
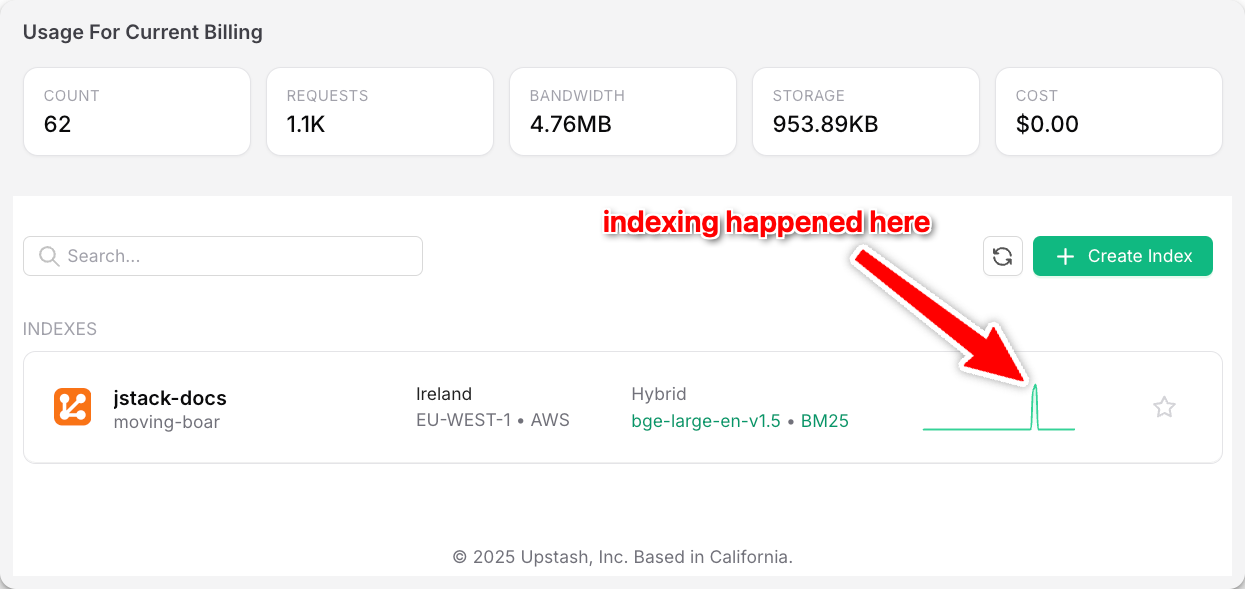
And that's it! We now have a hybrid index that combines literal and semantic search for the best possible results. We can even query it in natural language because it has an embedding model built in. Try running a query right in your Upstash dashboard!
To programmatically use this index to answer user questions, let's install @upstash/vector in our project and, if you're following along in JStack, create a simple middleware that makes our vector index accessible to all procedures:
import { Index } from "@upstash/vector";
import { env } from "hono/adapter";
import { jstack } from "jstack";
interface Env {
Bindings: {
UPSTASH_VECTOR_REST_URL: string;
UPSTASH_VECTOR_REST_TOKEN: string;
};
}
export const j = jstack.init<Env>();
export const vectorMiddleware = j.middleware(async ({ c, next }) => {
const { UPSTASH_VECTOR_REST_URL, UPSTASH_VECTOR_REST_TOKEN } = env(c);
const index = new Index({
url: UPSTASH_VECTOR_REST_URL,
token: UPSTASH_VECTOR_REST_TOKEN,
});
return await next({ index });
});
/**
* Public (unauthenticated) procedures
*
* This is the base piece you use to build new queries and mutations on your API.
*/
export const publicProcedure = j.procedure;We now laid the ground work: we created a hybrid vector index, inserted searchable documents into it and set up the Upstash Vector SDK to now programatically access this data from our app.
4. (Optional) Re-rank and Weight Documents
I wanted to include this step even though it is not relevant to our search demo. In real-world applications, you'll often find re-rankers and custom weights assigned to documents. For example, a document may be prioritized in search based on:
- User engagement metrics (view counts, time-on-page)
- User satisfaction with previous search results
- Conversion rates when specific results appear
You can get as complex as you want, and realistically, this plays a role when building enterprise-level search with direct revenue impact. It's something I learned while studying E-Commerce in university, and it's very relevant in practice. For this demo (and basically any search I've ever built) it would be complete overkill.
Still, I find it super interesting to put demos and small-to-medium sized applications into perspective with actual enterprise work.
5. Render Documents on the Frontend
We're all ready to use the vector index to process the user query and find relevant documents:
import { z } from "zod";
import { j, publicProcedure, vectorMiddleware } from "../jstack";
type SearchMetadata = {
title: string;
path: string;
level: number;
type: string;
content: string;
documentTitle: string;
};
export const searchRouter = j.router({
byQuery: publicProcedure
.use(vectorMiddleware)
.input(z.object({ query: z.string().min(1).max(1000) }))
.get(async ({ c, ctx, input }) => {
const { index } = ctx;
const { query } = input;
const res = await index.query<SearchMetadata>({
topK: 10,
data: query,
includeMetadata: true,
});
return c.superjson(res);
}),
});And that's all of the heavy lifting done! 🎉
Once we type a query into our input and the debounce threshold passes, our server automatically answers the query with relevant documents (full-text search and semantic search) from our Upstash Vector database.
Finally, this is our complete and final search bar component to display the search results:
"use client";
import { client } from "@/lib/client";
import { InferOutput } from "@/server";
import { useQuery } from "@tanstack/react-query";
import { useRef, useState } from "react";
import { useDebounce } from "../hooks/use-debounce";
type SearchOutput = InferOutput["search"]["byQuery"];
export const SearchBar = () => {
const [searchTerm, setSearchTerm] = useState("");
const debouncedSearchTerm = useDebounce(searchTerm, 150);
const prevResultsRef = useRef<SearchOutput>([]);
const { data: results, isRefetching } = useQuery({
queryKey: ["search", debouncedSearchTerm],
queryFn: async () => {
if (!debouncedSearchTerm) return [];
const res = await client.search.byQuery.$get({
query: debouncedSearchTerm,
});
const newResults = await res.json();
prevResultsRef.current = newResults;
return newResults;
},
initialData: [],
enabled: debouncedSearchTerm.length > 0,
placeholderData: () => prevResultsRef.current,
});
const displayedResults = isRefetching ? prevResultsRef.current : results;
return (
<div className="mx-auto mt-20 flex w-full max-w-sm flex-col items-center justify-center">
<input
placeholder="Search..."
className="w-full rounded-lg border border-zinc-700 bg-zinc-800/70 px-4 py-2.5 text-zinc-100 placeholder-zinc-400 outline-none transition-all duration-200 focus:border-[#00e9a3] focus:ring-2 focus:ring-[#00e9a3]/50"
value={searchTerm}
onChange={(e) => setSearchTerm(e.target.value)}
/>
{displayedResults.length > 0 && (
<div className="relative mt-2 min-h-0 w-full flex-1 rounded-lg border border-zinc-700/50 bg-zinc-800/50 shadow-lg backdrop-blur-sm">
<div className="pointer-events-none absolute inset-x-0 top-0 z-10 h-4 bg-gradient-to-b from-zinc-800/95 to-transparent" />
<ul
className="scrollbar-thin scrollbar-thumb-zinc-600 scrollbar-track-zinc-800/30 h-full max-h-[32rem] overflow-y-auto overflow-x-hidden pr-2"
role="listbox"
style={{
scrollbarWidth: "thin",
scrollbarColor: "#52525b #27272a",
}}
>
{displayedResults.map((result, index) => (
<li
key={index}
id={`result-${index}`}
role="option"
className="mx-1 my-1 cursor-pointer rounded-lg px-4 py-4 transition-colors duration-150 hover:bg-zinc-700/50"
onClick={() => {
if (result.metadata) {
// normally: push to URL on select
console.log("Selected:", result.metadata.title);
}
}}
>
<h3 className="text-lg font-medium text-zinc-100">
{result.metadata?.documentTitle || ""}
</h3>
<p className="mt-1 text-sm text-[#00e9a3]">
{result.metadata?.title || ""}
</p>
<p className="mt-2 text-sm leading-relaxed text-zinc-300">
{result.metadata?.content
? result.metadata.content.length > 125
? `${result.metadata.content.substring(0, 125)}...`
: result.metadata.content
: ""}
</p>
</li>
))}
</ul>
</div>
)}
</div>
);
};Conclusion
We just built a typo-tolerant full-text + semantic search engine! The results look like this:
One thing I would like to see that Upstash Vector does not yet support is custom re-ranking of results and synonyms. These could improve the search quality even more. Other than that, I really liked how easy this was to implement, and that the best results are usually at or near the top of the search.
You can find the full production implementation in the open source JStack GitHub repository. :)
Cheers for reading! If you have any feedback or would like to be a guest author on Upstash, drop me a line at josh@upstash.com 🙌