How We Made QStash And Upstash Workflow Reliable At Scale

When users rely on a platform like QStash and Upstash Workflow for production operations, reliability stops being a nice-to-have. It becomes the product.
Over the last few months, we have been working on making the system more stable under real-world load. Some of that work came from good initial design decisions. Some of it came from new problems that only appeared as usage grew.
In this post, I want to talk about both: the architectural choices that gave us a strong foundation, and the lessons we learned as the system encountered more demanding workloads.
Designing for growth from the beginning
One of the earliest decisions we made was that QStash should not depend on a single machine growing forever.
That sounds obvious, but it shapes a surprising number of downstream decisions. In a growing system, you do not always know in advance which resource becomes constrained first. Sometimes it is CPU. Sometimes memory. Sometimes disk. Often, the limiting factor changes over time as workloads shift.
Because of that, we designed QStash to scale horizontally across all three.
Storage that can grow with the system
QStash uses Upstash Redis databases as its storage layer. Rather than relying on a single Redis instance, we maintain a pool of databases and expand that pool as needed.
User resources and tasks are distributed across these databases, which means storage growth does not require a disruptive migration to a larger single node. Capacity can be added incrementally.
This gives us a straightforward way to scale disk and storage throughput as the system grows.
Compute that tolerates failure
On the compute side, we run a cluster of QStash processes, each capable of doing the same work.
That symmetry is useful for two reasons. First, it makes the system resilient: if one process goes down, the others can detect it and continue processing. Second, it makes scaling simple: when traffic increases, we can increase the number of processes without changing the overall design.
This architecture gave us a strong foundation. For a long time, it was enough.
But production systems do not only grow in size. They also grow in behavioral complexity. New users bring new traffic patterns, new failure modes, and new assumptions that your original design may not have fully accounted for.
That is where things got interesting.
Reliability problems that only appear later
The most instructive reliability issues are rarely the ones you plan for on day one.
They tend to emerge slowly, often from legitimate user behavior interacting with the system in ways that look harmless at first. A workload becomes burstier. Payloads become larger. Endpoints become less responsive. A subsystem that was fine at one scale becomes fragile at another.
We ran into several of these. Three of them were especially important.
1. Bursty traffic and large payloads
One of the first problems we hit was a simple but dangerous combination: bursty traffic carrying large messages.
The issue was not sustained load. Sustained load is often easier to reason about because autoscaling has time to react. The harder case was a sudden increase in memory usage within a very small window. In those moments, a process could move toward an out-of-memory condition faster than new capacity could be added.
That kind of failure mode is particularly unpleasant because it compresses the time available to respond. By the time a human notices the problem, it may already have become a crash loop.
So we added a pressure valve.
A memory-aware fetch limit
The key idea was straightforward: when the process is already under significant memory pressure, it should stop pulling in more work that could make the situation worse.
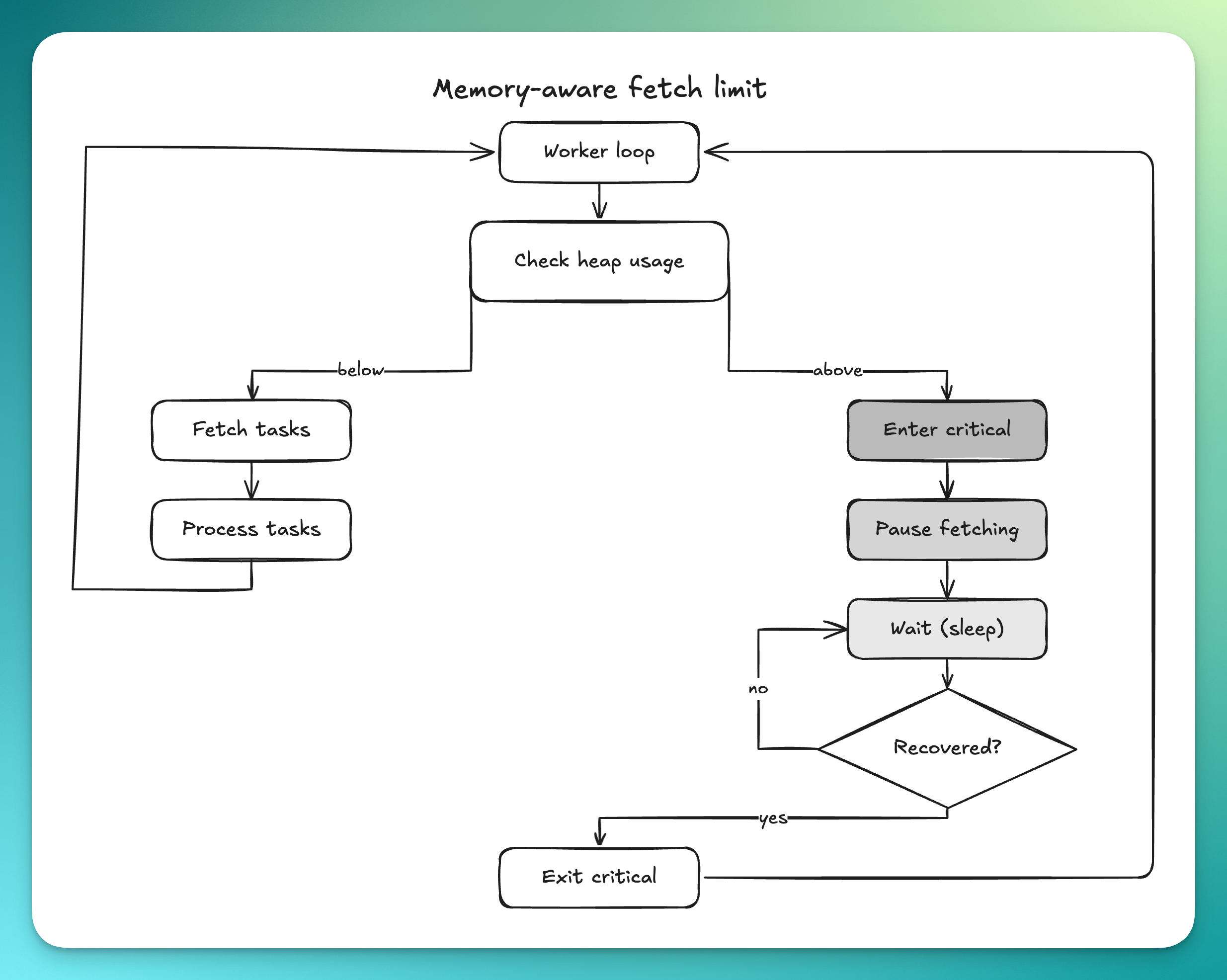
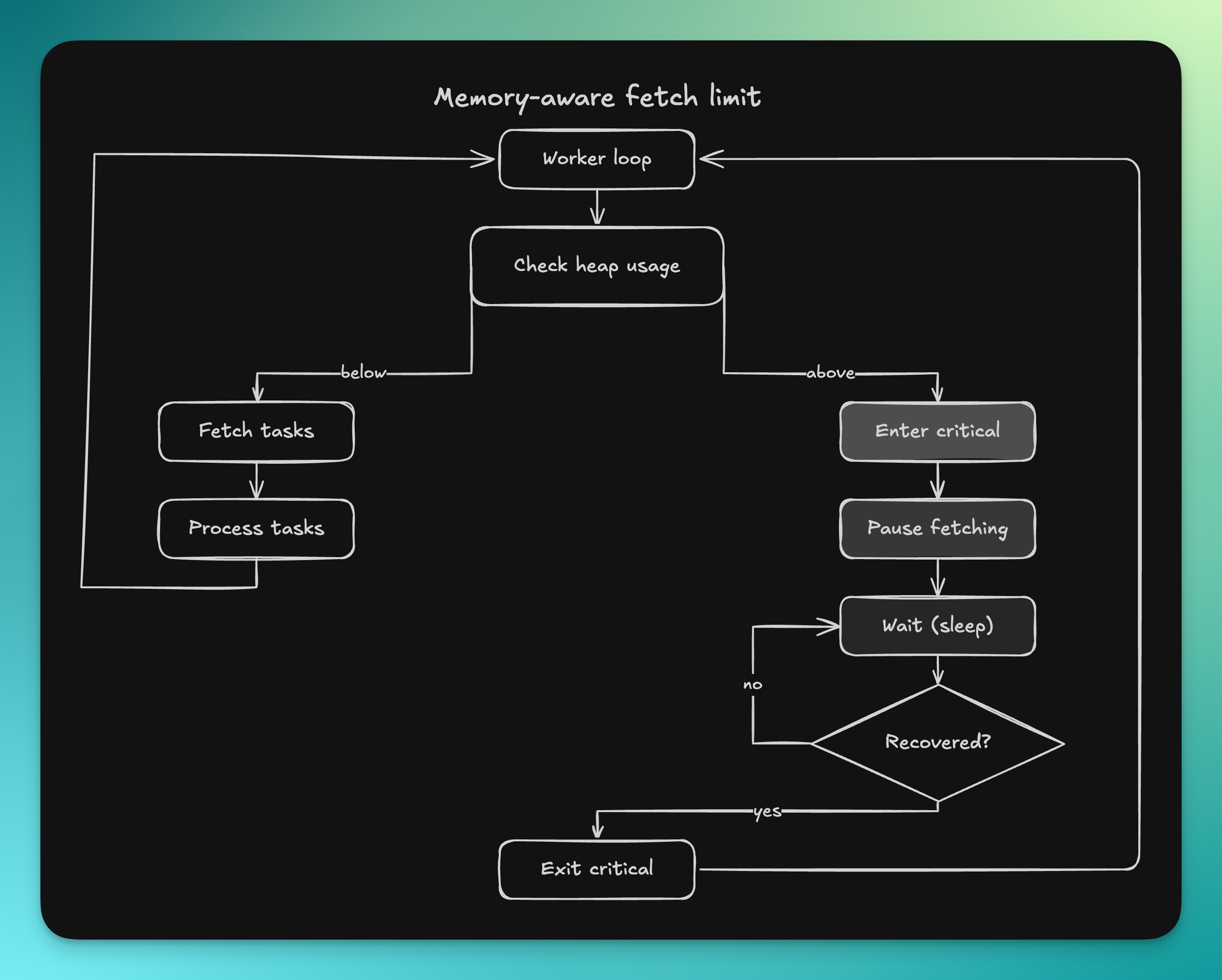
We introduced a goroutine that continuously tracks memory usage and flips the system into a critical state when heap usage crosses a configurable threshold. That threshold is based on the memory limit of the machine, with headroom reserved for overhead the application does not directly control, such as socket buffers, file cache, and runtime internals.
A simplified version of that logic looks like this:
var memoryCritical atomic.Bool
func keepTrackForFetchLimit(ctx context.Context) {
ticker := time.NewTicker(time.Second)
defer ticker.Stop()
for {
select {
case <-ticker.C:
var heapInuse = readHeapUsage()
var memLimit = debug.SetMemoryLimit(-1)
var fLimit = memLimit * fetchLimitPercentage.Load() / 100
isCritical := heapInuse >= fLimit
if memoryCritical.Load() == isCritical {
continue
}
memoryCritical.Store(isCritical)
if isCritical {
logger.Error().Msgf(
"High heap memory usage! Used-Heap: %s, Fetch-Limit: %s, Memory-Limit: %s",
bytes.Size(heapInuse),
bytes.Size(fLimit),
bytes.Size(memLimit),
)
runtime.GC()
} else {
logger.Info().Msgf(
"Memory usage back to normal! Used-Heap: %s, Fetch-Limit: %s, Memory-Limit: %s",
bytes.Size(heapInuse),
bytes.Size(fLimit),
bytes.Size(memLimit),
)
}
case <-ctx.Done():
return
}
}
}Once that state is set, memory-heavy fetch paths call a second function and simply wait until the process is below the critical threshold again:
func WaitForMemoryBelowFetchLimit(ctx context.Context) {
if !memoryCritical.Load() {
return
}
ticker := time.NewTicker(time.Second)
defer ticker.Stop()
for {
select {
case <-ctx.Done():
return
case <-ticker.C:
if !memoryCritical.Load() {
return
}
}
}
}Slowing down the right parts of the system
We use this safeguard in the places where a single polling cycle can suddenly bring in a large amount of data.
That includes worker goroutines checking for deliverable tasks, queue pollers reading from Redis, and the pipeline that exports raw user logs to an external logging service.
In normal conditions, these components continuously fetch work. But when memory usage is already in a critical zone, they pause before the next fetch instead of making the problem worse.
This is a form of backpressure, but it is intentionally local and temporary. The goal is not to stop the system. The goal is to avoid turning a period of high pressure into a crash.
Making sure backpressure does not become silent failure
There is an important subtlety here: delaying user work to avoid an out-of-memory crash is the correct decision, but it is still a degraded mode.
So this mechanism cannot be allowed to fail quietly.
Whenever the system enters the critical state, it emits an error log that wakes up our on-call engineer. That gives us a chance to respond operationally by adding capacity before users start noticing meaningful delays.
This matters because a system can otherwise become “safe” in the narrow sense while still being unhealthy in practice. It may avoid crashing, but if work stalls and nobody knows, users are still affected. In infrastructure, discovering problems from user reports is usually a sign that your detection came too late.
2. When user endpoints stop responding
The second issue was not inside QStash itself, but at the boundary between our system and user infrastructure.
QStash and Upstash Workflow call user endpoints. Over time, we noticed that some of those endpoints do not fail fast when they break. They simply stop responding. Sometimes for hours. Sometimes for days.
At first glance, retries seem like the obvious answer. And retries are part of the product promise. But retries are not free. If an endpoint is persistently unhealthy and nobody is repairing it, retrying aggressively does not improve delivery. It mostly consumes memory, queue capacity, and processing time.
At some point, that stops being one user’s problem and starts becoming everyone else’s problem too.
A host-aware blocker
To contain this, we introduced a HostBlocker algorithm.
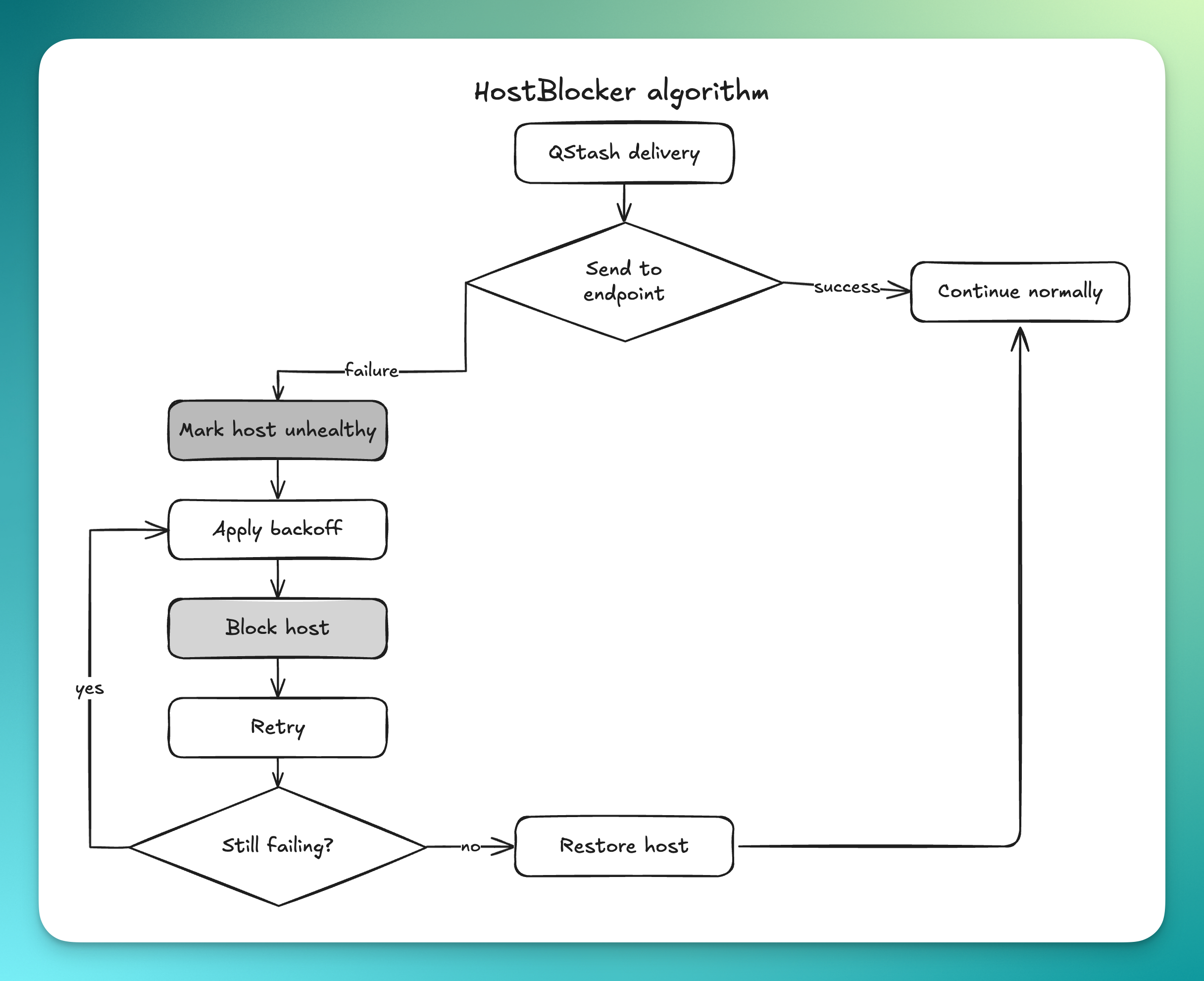
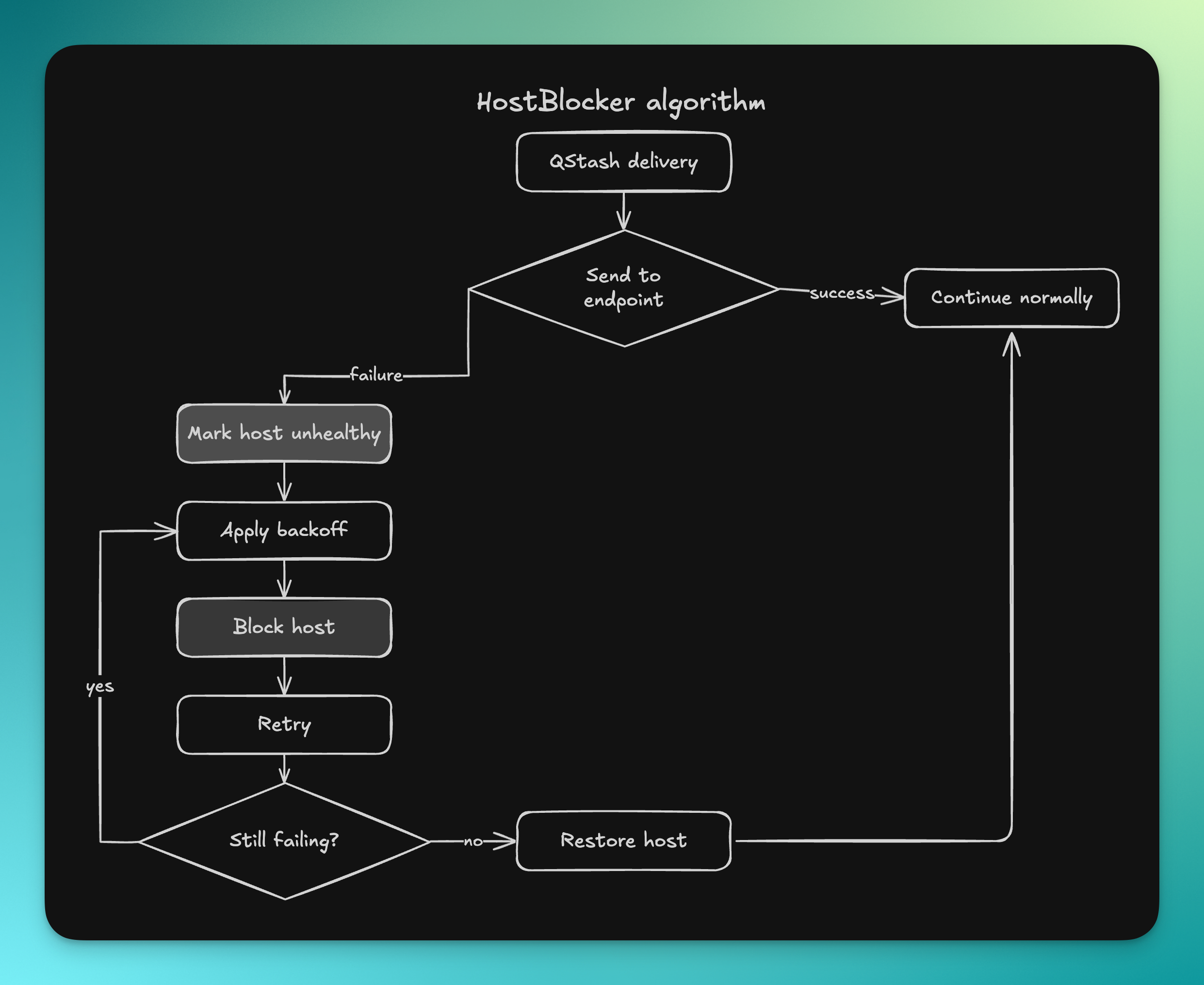
If a user endpoint times out, we do not keep sending requests to it at full speed. Instead, we move that host into a temporary blocked state and wait before retrying. If the timeouts continue, the wait time increases.
The effect is simple: unhealthy destinations gradually receive less pressure from the system.
This helps in two ways. First, it protects shared infrastructure from being dominated by traffic that has little chance of succeeding. Second, it allows healthy user traffic to continue flowing instead of competing with endpoints that are effectively down.
We also added an administrative override so that when a user fixes their system and contacts us, we can move the host back to the allowlist immediately.
There is a broader lesson here. Reliability is not just about retrying failures. It is also about isolating them.
3. Replacing systems before they become emergencies
Some reliability work is reactive. A new failure mode appears, and you build a guardrail around it.
But some of the most important work is quieter than that. It is recognizing that a subsystem is reaching the limit of what it was designed for, and replacing it before it becomes a visible outage.
We had to do that in at least two places.
Flow control
One example was our flow control implementation.
As QStash grew, the original design started limiting what we could offer users in terms of scaling behavior, observability, and control. We rewrote it so that it could behave more predictably under load and expose better controls to users.
That rewrite is substantial enough that it deserves its own post, which we published here:
Rewriting Flow Control in QStash and Workflow
Logging
The other example was logging.
Our first implementation used SQLite. But as data volume continued to increase, SQLite became a limiting factor for the kinds of queries and scale we needed to support.
Eventually, we migrated to Elasticsearch.
The migrations themselves were not the interesting part. The operational strategy was.
We wanted these changes to be invisible to users, so we avoided cutovers that depended on a single moment going perfectly. Instead, we dual-wrote into both the old and new systems for weeks. Once the new system had accumulated enough history to serve real traffic—up to the retention window users expect—we gradually switched reads over.
Even then, we kept the old system alive for a while as a fallback until we were confident the new one was stable.
That approach costs more during the migration period. But it turns migration risk into something much easier to reason about. The system stays reversible for longer, and users are not forced to participate in the transition accidentally.
Reliability is a moving target
One of the humbling things about running infrastructure is that reliability is never finished.
A design that is correct today may be incomplete tomorrow. A subsystem that behaves well at one traffic shape may degrade under another. Features that appear unrelated to reliability—logging, flow control, queue polling—often become central to it as the platform matures.
That is part of the job.
When your system sits inside someone else’s production path, you inherit a certain obligation. You are not just building features. You are making promises about behavior under stress, and then continuously earning the right to keep making them.
That work is challenging. It is also rewarding.
And as QStash continues to grow, we expect it to reveal new problems we have not seen yet. That is not something we fear. Those are usually the most valuable problems—the ones that only show up when real users are depending on you for real workloads.
Those are the problems worth solving.