Resumable AI SDK v5 Streams with Upstash Realtime

A few weeks ago, I accidentally created a new Upstash product: Upstash Realtime. It's a Pusher/Ably alternative using Redis Streams to add realtime features to your app. Perfect for Next.js and absolutely deployable to Vercel (because that's what I use).
Here's a quick demo of what we're building 👇
Most AI chat apps have a problem. If you lose connection, refresh the page, or close your laptop, you lose the entire AI generation. You need to start over and wait for the whole thing again.
This sucks especially for long generations with expensive models or when running complex AI workflows that take 20+ seconds.
An AI chat that:
- Streams responses in real-time w/ AI SDK v5
- Runs in a reliable background job with Upstash Workflow
- Survives page refreshes or network disconnects
- Can be viewed on multiple devices at the same time
- Perfectly resumable and extremely fast
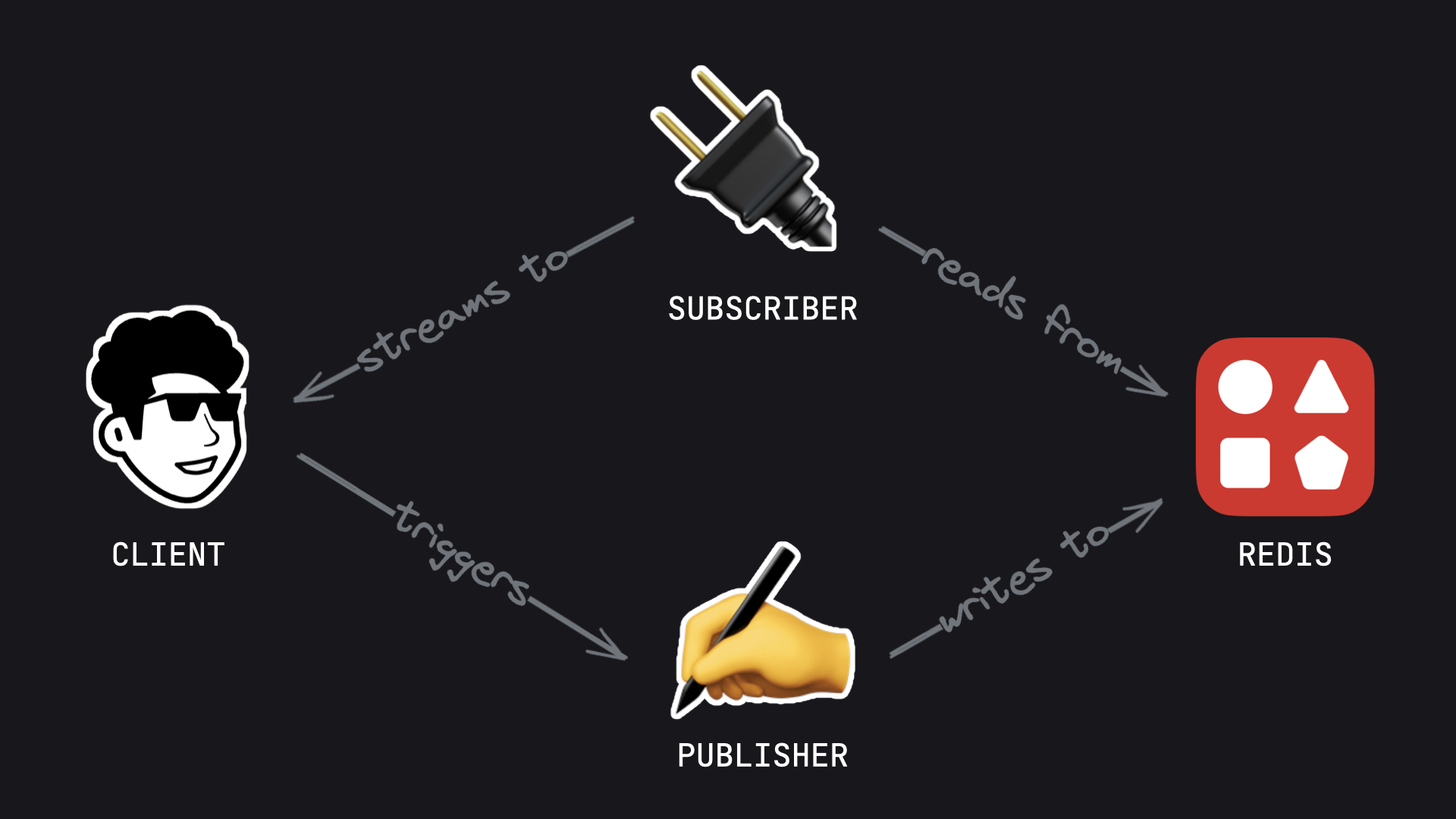
From an engineering perspective, I'd illustrate it like this:
By the way, everything we're building here is 100% open-source.
Setup
First, let's install the package:
npm install @upstash/realtimeWe'll need two things from the Upstash dashboard:
- Redis - for storing chat history
- QStash - for running Workflow
Both have a big free tier. Create them at console.upstash.com.
Add these to your .env:
UPSTASH_REDIS_REST_URL="..."
UPSTASH_REDIS_REST_TOKEN="..."
QSTASH_TOKEN="..."Step 1: Set up libraries
Let's create these three files:
import { Redis } from "@upstash/redis";
export const redis = Redis.fromEnv();import { InferRealtimeEvents, Realtime } from "@upstash/realtime";
import { UIMessageChunk } from "ai";
import z from "zod/v4";
import { redis } from "./redis";
// 👇 the event we're gonna emit in real-time later
// the AI SDK v5 doesn't provide a chunk zod schema, so we'll go with `z.any()`
export const schema = {
ai: { chunk: z.any() as z.ZodType<UIMessageChunk> },
};
export const realtime = new Realtime({ schema, redis });
export type RealtimeEvents = InferRealtimeEvents<typeof realtime>;import { createOpenRouter } from "@openrouter/ai-sdk-provider";
export const openrouter = createOpenRouter({
apiKey: process.env.OPENROUTER_API_KEY,
});I'm using OpenRouter here (because I use it in production, too), but you can use any AI SDK provider (OpenAI, Anthropic, etc).
Step 2: The backend
Here's where it gets interesting. We're using Upstash Workflow to run the AI generation as a background job. This means the generation continues even if the user disconnects.
import { openrouter } from "@/lib/openrouter";
import { realtime } from "@/lib/realtime";
import { redis } from "@/lib/redis";
import { serve } from "@upstash/workflow/nextjs";
import { convertToModelMessages, streamText, UIMessage } from "ai";
export const GET = async (req: Request) => {
const { searchParams } = new URL(req.url);
const id = searchParams.get("id");
if (!id) return new Response("ID is required.");
const channel = realtime.channel(id);
const stream = new ReadableStream({
async start(controller) {
// 👇 replay all AI chunks from history
await channel.history().on("ai.chunk", (chunk) => {
controller.enqueue(`data: ${JSON.stringify(chunk)}\n\n`);
if (chunk.type === "finish") controller.close();
});
},
});
return new Response(stream, {
headers: { "Content-Type": "text/event-stream" },
});
};
export const { POST } = serve(async (workflow) => {
const score = Date.now();
const { id, message } = workflow.requestPayload as {
id: string;
message: UIMessage;
};
// 👇 save user message to history
await redis.zadd(`history:${id}`, { nx: true }, { score, member: message });
await workflow.run("ai-generation", async () => {
// 👇 load chat history
const history = await redis.zrange<UIMessage[]>(`history:${id}`, 0, -1);
const result = streamText({
model: openrouter.chat("google/gemini-2.5-flash-lite"),
system:
"Use markdown and headings 1-3 to nicely format your response. Use a few emojis.",
messages: convertToModelMessages([...history, message]),
});
const stream = result.toUIMessageStream({
generateMessageId: () => crypto.randomUUID(),
onFinish: async ({ messages }) => {
// 👇 save AI response to history
for (const member of messages) {
await redis.zadd(`history:${id}`, { score: Date.now(), member });
}
},
});
// 👇 emit each chunk to the `GET` handler above
const channel = realtime.channel(message.id);
for await (const chunk of stream) {
await channel.emit("ai.chunk", chunk);
}
});
});Let me explain what's happening:
GET endpoint: This is what the client connects to. It replays all AI chunks from history using channel.history(). This means if we reconnect, we replay all chunks up until the current generation.
POST endpoint: This runs as a Workflow background job. It:
- Saves the user message to Redis
- Loads chat history
- Streams the AI response
- Emits each chunk in real-time
- Saves the final AI response to Redis when done
Important: the AI stream runs without any persistent connection to the client. The client keeps a persistent but interruptible connection to a separate subscriber.
Step 3: Resumable Transport
The AI SDK needs a custom transport to work with our backend. This transport handles reconnection and honestly is the only piece of 'ugly' code we need to make resumable streams work. Because it's kinda ugly, let's put it into another file:
import { DefaultChatTransport } from "ai";
export const createResumableTransport = ({
messageId,
setChatId,
setMessageId,
}: {
messageId: string | null;
setChatId: (id: string | null) => any;
setMessageId: (id: string | null) => any;
}) =>
new DefaultChatTransport({
async prepareSendMessagesRequest({ messages, id }) {
await setChatId(id);
return { body: { message: messages[messages.length - 1], id } };
},
prepareReconnectToStreamRequest: (data) => {
return {
...data,
headers: { ...data.headers, "x-is-reconnect": "true" },
};
},
fetch: async (input, init) => {
const headers = new Headers(init?.headers);
if (headers.get("x-is-reconnect") === "true") {
return fetch(input + `?id=${messageId}`, {
...init,
method: "GET",
});
}
const { id } = JSON.parse(init?.body as string).message;
await setMessageId(id);
const [res] = await Promise.all([
// 👇 subscribe to stream
fetch(input + `?id=${id}`, { method: "GET" }),
// 👇 trigger workflow
fetch(input, init),
]);
return res;
},
});This transport does two things:
- Write: Triggers the background job (only once per message)
- Read: Connects to the Realtime stream using SSE
Step 4: Frontend Chat Component
Now let's build (a basic) chat UI:
"use client";
import { createResumableTransport } from "@/lib/resumable-transport";
import { useChat } from "@ai-sdk/react";
import type { UIMessage } from "ai";
import { useQueryState } from "nuqs";
import { useEffect, useRef, useState } from "react";
export const Chat = ({
initialHistory,
}: {
initialHistory: Record<string, UIMessage[]>;
}) => {
const [input, setInput] = useState("");
const [messageId, setMessageId] = useQueryState("messageId");
const [chatId, setChatId] = useQueryState("chatId", { defaultValue: "" });
const inputRef = useRef<HTMLInputElement>(null);
// we use a Record<> so we can clear messages by changing the chatId
// otherwise, we'd keep the messages in history, even with a new chatId
const history = initialHistory[chatId] ?? [];
useEffect(() => {
// 👇 generate chat ID on mount
if (!chatId) setChatId(crypto.randomUUID());
}, [chatId]);
const { messages, sendMessage, status } = useChat({
id: chatId ?? undefined,
// 👇 resume if we're reconnecting to a pending AI response
resume: Boolean(history.at(-1)?.id === messageId),
messages: history,
transport: createResumableTransport({ messageId, setChatId, setMessageId }),
});
const handleSubmit = (e: React.FormEvent) => {
e.preventDefault();
if (!input.trim()) return;
sendMessage({ text: input });
setInput("");
};
return (
<div className="mx-auto flex h-screen max-w-2xl flex-col p-4">
<div className="mb-4 flex-1 space-y-4 overflow-y-auto">
{messages.map((message) => (
<div
key={message.id}
className={`rounded-lg p-4 ${
message.role === "user"
? "ml-auto max-w-[80%] bg-blue-100"
: "mr-auto max-w-[80%] bg-gray-100"
}`}
>
{message.parts.map((part, i) =>
part.type === "text" ? <div key={i}>{part.text}</div> : null,
)}
</div>
))}
</div>
<form onSubmit={handleSubmit} className="flex gap-2">
<input
ref={inputRef}
value={input}
onChange={(e) => setInput(e.target.value)}
placeholder="Type a message..."
disabled={status === "streaming"}
className="flex-1 rounded-lg border p-2"
/>
<button
type="submit"
disabled={status === "streaming"}
className="rounded-lg bg-blue-600 px-4 py-2 text-white disabled:bg-gray-400"
>
Send
</button>
</form>
</div>
);
};The useChat hook handles the reconnection via our transport. We resume if the last message in history is a user message, which means the AI response is not finished yet.
Step 5: Server component for history
Let's wrap the Chat component with a simple server component to load history from Redis:
import { Chat } from "@/components/chat";
import { redis } from "@/lib/redis";
import { UIMessage } from "ai";
type Params = Promise<{ chatId?: string }>;
const Page = async ({ searchParams }: { searchParams: Params }) => {
const { chatId } = await searchParams;
// 👇 load chat history from Redis
const history = await redis.zrange<UIMessage[]>(`history:${chatId}`, 0, -1);
return <Chat initialHistory={chatId ? { [chatId]: history } : {}} />;
};
export default Page;This loads the entire chat history from Redis on page load. The client gets the full conversation so we know whether to resume or not.
How Resumability Works
We've moved all persistent connections away from the Publisher (piece of logic that runs the AI stream) and moved them to an independent Subscriber. Architecturally it looks like this:
- User sends a message
- Frontend triggers the POST endpoint (Workflow starts)
- Frontend connects to GET endpoint (Realtime stream)
- Workflow generates AI response, emits chunks to Realtime
- Frontend receives chunks in real-time via SSE
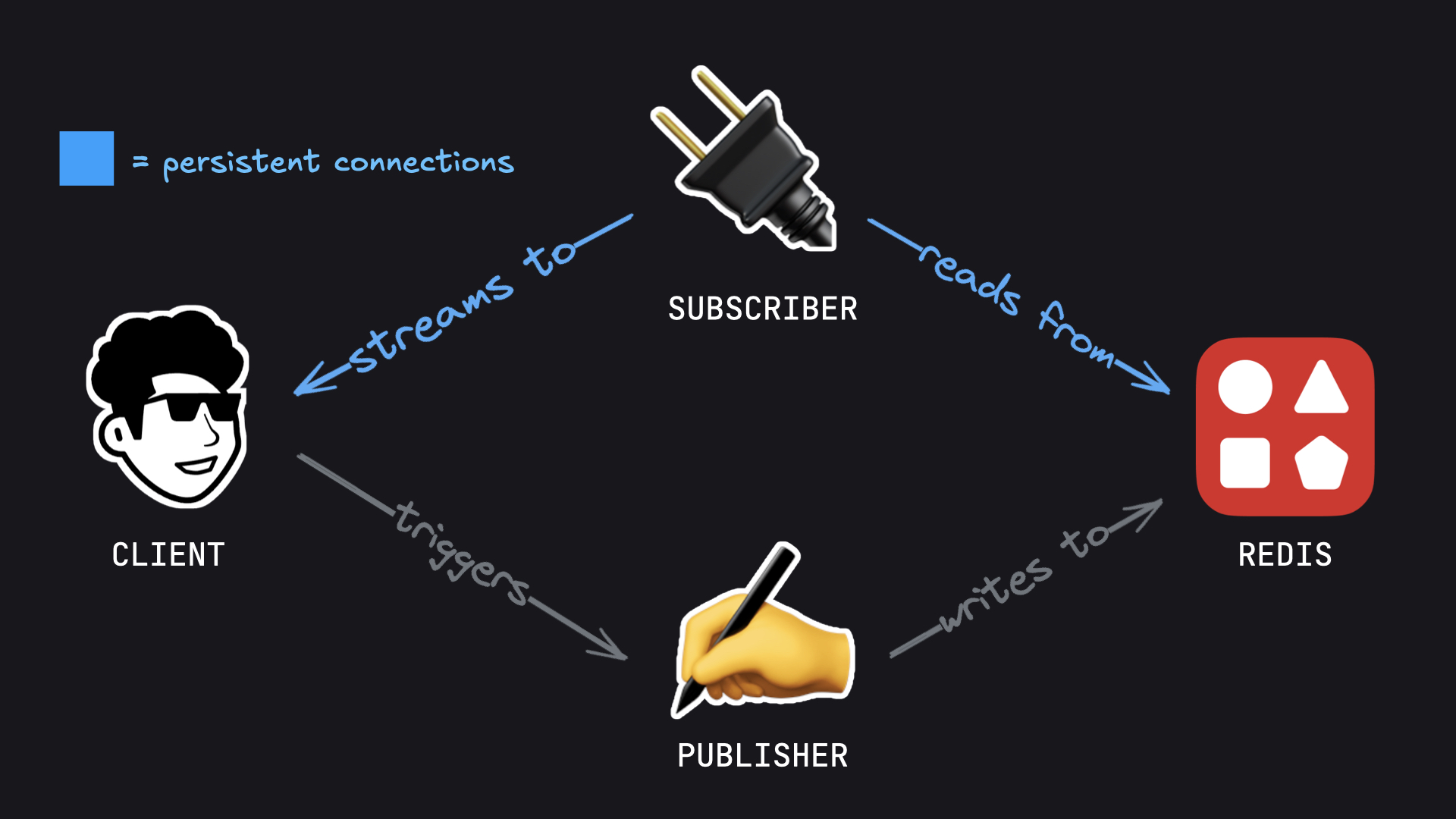
If connection breaks:
- Frontend reconnects to GET endpoint
channel.history()replays all chunks for the currentmessageId- Stream replays until current chunk and subscribes to all future chunks
The Workflow job never stops (unless you'd want to explicitly stop it). It keeps generating and emitting chunks. The client automatically replays messages when it reconnects.
Regular streaming vs. resumable streaming
"Traditional" streaming:
- Client is directly connected to Publisher
- Publisher has 2 responsibilities: Running stream & streaming to client
- Generation stops if connection breaks
- Can't view on multiple devices
Resumable streams:
- Publisher only has single responsibility: Running stream
- Generation continues in background
- View same stream on phone and laptop
- Full history replay on reconnect
- Only downside: Durable streams use Redis commands (can cost at scale). BUT: Upstash Redis has fixed instances w/ unlimited commands for $10/mo :]
The user experience is a LOT better. That's why companies like OpenAI or T3Chat use resumable streams.
Appreciate you for reading! 🙌 Questions or feedback? Always DM me @joshtriedcoding or email me at josh@upstash.com.