

Context7 gives LLMs access to up-to-date documentation, so they stop hallucinating outdated APIs. We just updated its architecture to dramatically reduce context bloat. Here's what changed:
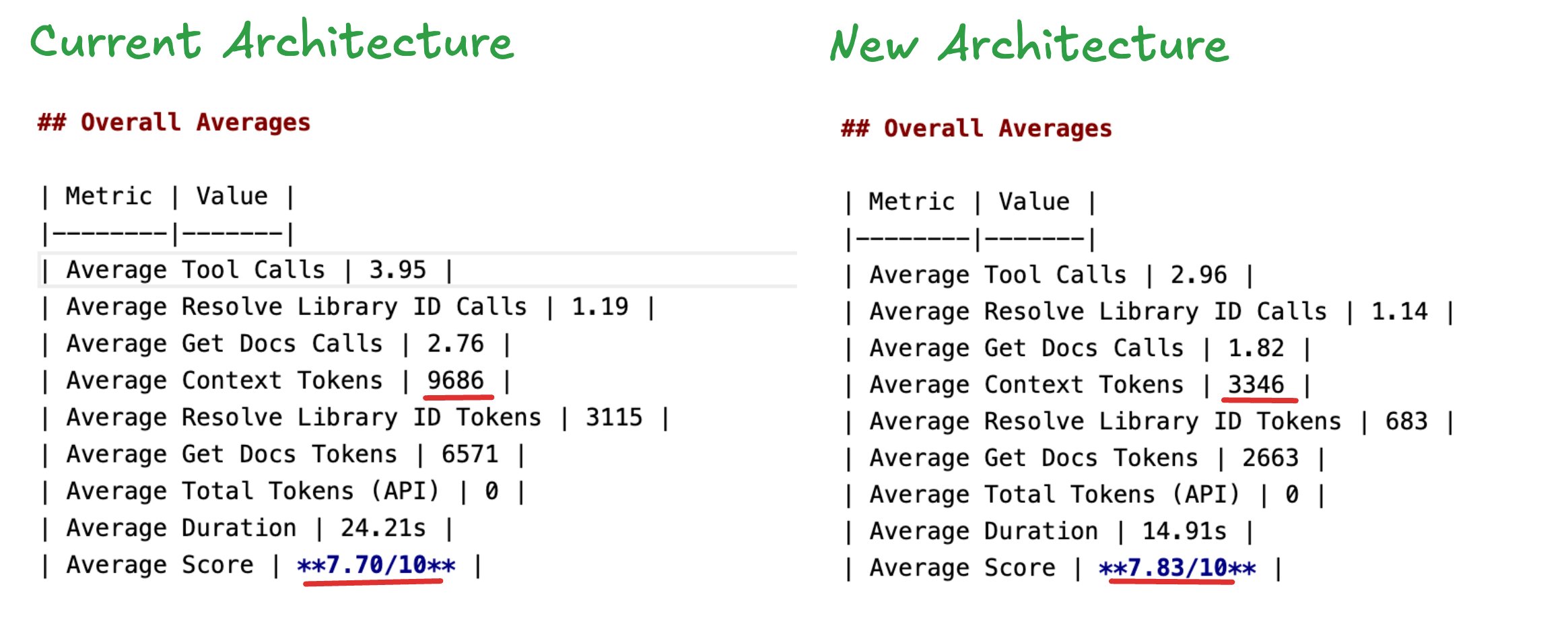
- Tokens ↓ 65% — from ~9.7k to ~3.3k average context tokens
- Latency ↓ 38% — from 24s to 15s average duration
- Tool calls ↓ 30% — from 3.95 to 2.96 average calls
- Quality ↑ — slight improvement in internal benchmark scores across real MCP queries
At a high level, the change is simple: instead of asking the LLM to repeatedly search and filter documentation, Context7 now does that work itself and sends back only the pieces that actually answer the question.
In this post, we'll describe the background and how we got here.
Previously, Context7 worked like this: when an AI makes a request through MCP, it's a two-step process. The first call resolves a library name to a Context7 ID. The second call fetches the actual documentation from our vector database:
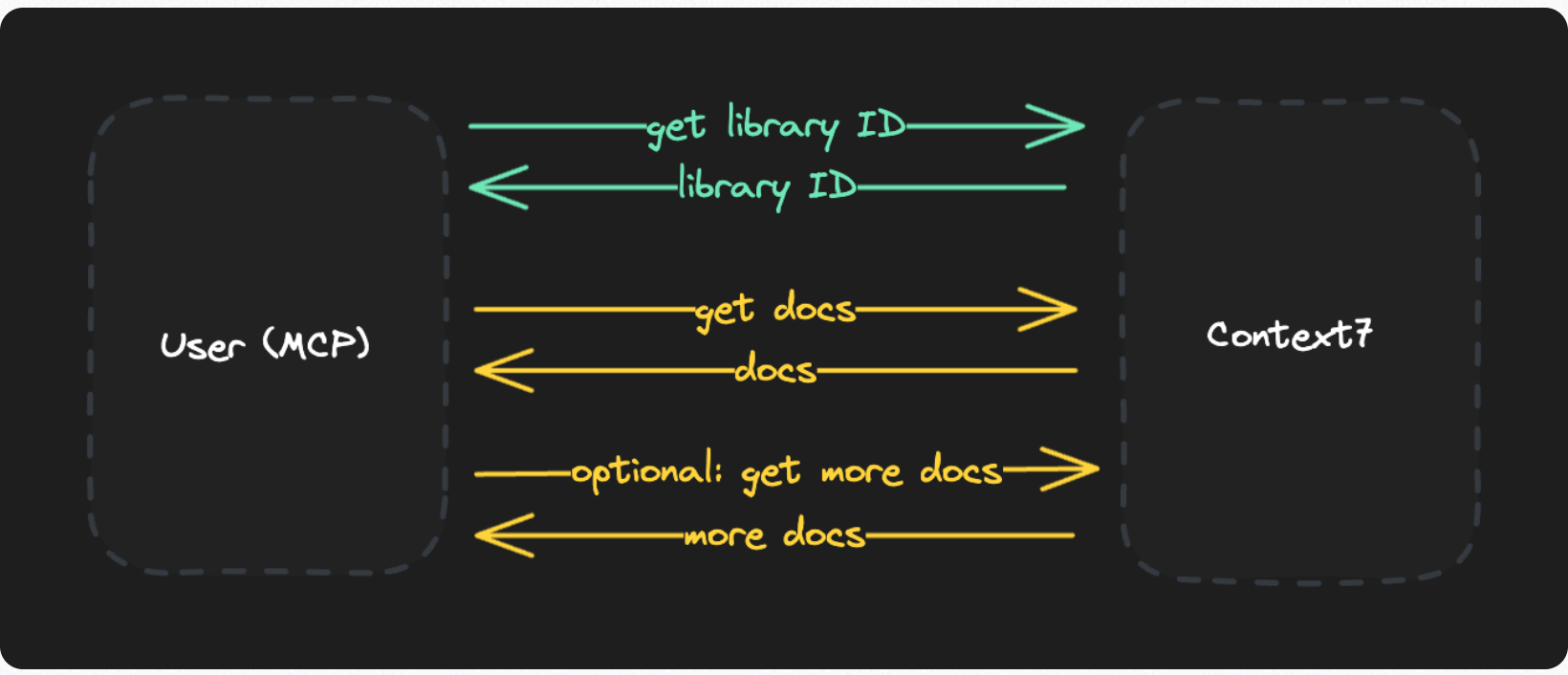
The problem: The MCP keeps calling the server again and again until it finds the best result. Each call adds to the context window, and by the time it's done searching, we end up with more expensive generations and potentially worse output (this is also called "context bloat").

We knew we could do better. So we moved the filtering and ranking work to our side. Instead of returning everything the vector database finds and letting your AI model figure out what's useful, we now do high-quality reranking on the server using fast reranking models.
That way, the model only gets back the specific documentation pieces that answer the query. It's actually faster too, since there's no back-and-forth. The only real trade-off is on our end. Each request now costs us more because we run reranking in addition to vector search.
We're intentionally making this trade-off. Filtering and ranking documentation is cheaper, faster, and more predictable on our infrastructure than asking a general-purpose reasoning model to do it as part of generation. In practice, this means users pay less in tokens and get more stable results.
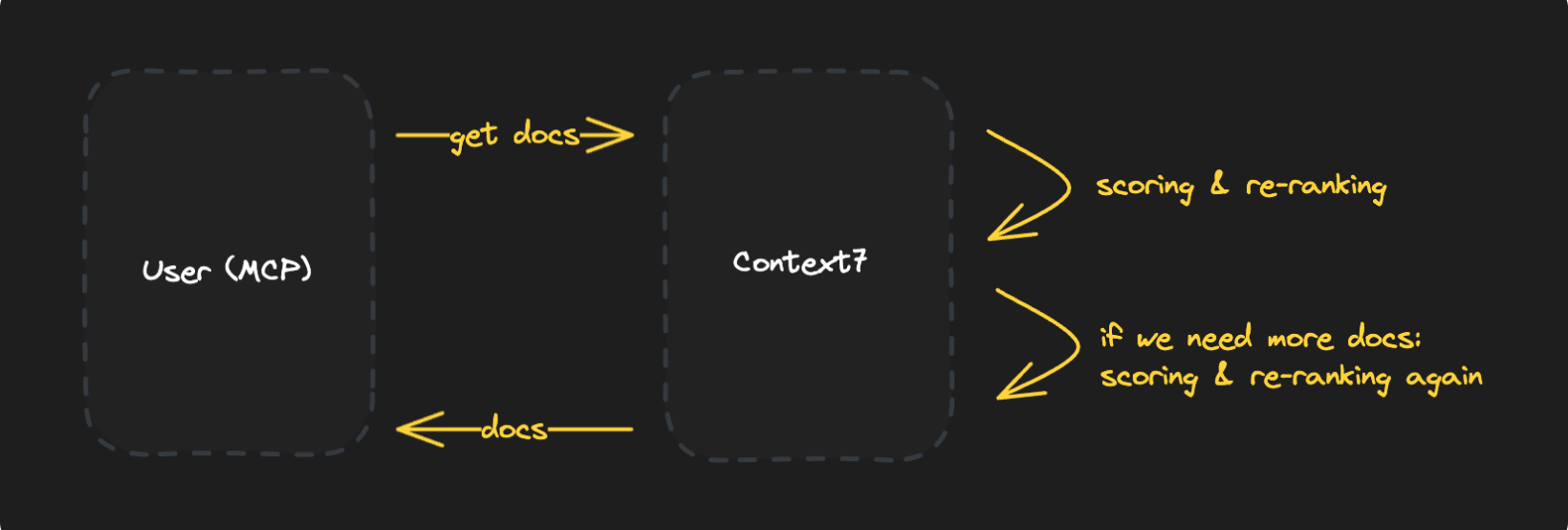
We apply reranking for both library queries and context queries. Instead of handing back everything the vector database finds:
- We give the best results early, preventing LLMs from making repeated calls
- Send back less documentation, only the most relevant pieces
- Thereby consume (much) less context
This is a general infrastructure change, but let's use our SDK to illustrate the changes.
The new API
We still have two methods: searchLibrary and getContext. The key change is that both now accept a query string, giving our reranker the context it needs to return the best results. The practical impact is that you no longer have to think about pagination, result limits, or retrieval modes. You describe what you need, and Context7 decides what documentation is relevant enough to send back.
A note on privacy: The query sent to Context7 is generated by the LLM, not your original prompt. Your actual question never leaves your machine—we only receive the LLM's reformulated query for documentation lookup.
Searching for libraries
Instead of just passing a library name, you now pass a query describing what you need:
import { Context7 } from "@upstash/context7-sdk";
const client = new Context7();
// Search for libraries with a query
const libraries = await client.searchLibrary(
"I need to build a UI with components",
"react"
);
console.log(`Found ${libraries.length} libraries`);
console.log(libraries[0].id); // "/facebook/react"Getting documentation
We replaced getDocs with getContext. Instead of managing pagination and modes, we now just ask a question:
// Get documentation context as plain text (default)
const context = await client.getContext(
"How do I use hooks?",
"/facebook/react"
);
console.log(context);
// Get documentation as JSON array
const docs = await client.getContext("How do I use hooks?", "/facebook/react", {
type: "json",
});
console.log(docs[0].title, docs[0].content);By default we get back a string of the most relevant docs concatenated together. If you need structured data, pass { type: "json" }. The server-side reranker takes care of the complexity that was caused by mode and pagination before.
We also dropped defaultMaxResults. The API now returns relevant results without manual tuning.
Why We're Doing This
Judging from feedback, especially on Twitter, context bloat is the number 1 issue that holds people back from using Context7. Especially with the explosion of Opus 4.5, an extremely good but expensive model, it's more than enough to use a single or very few pieces of accurate documentation.
By reranking on our side, we move that filtering cost from the user (who likely uses an expensive model) to us (where we can use more cost-efficient models because reranking is fairly simple & fast).
As a nice bonus, the MCP also becomes simpler.
Another approach: Embed Context7 into an Agent
There's another way to optimize context usage: instead of the LLM calling Context7 as a tool, you can embed the Context7 client directly into an agent. This way, the agent does all the documentation lookup internally and returns only the final response to the user.
This is very efficient for context—your main LLM never sees the raw documentation at all. However we don't recommend this as the default for interactive coding workflows, where having the documentation visible to the model alongside the user's code tends to produce better, more grounded results.
If you're interested in trying this approach, here's a sample implementation: Context7 Agent with AI SDK
What's Next
We're closely monitoring and benchmarking the new release. We're actively looking for ways to improve both efficiency and quality of the results.
If you're using Context7, we'd love to hear what you're seeing in practice—especially around token usage, answer quality, and cases where reranking missed or over-prioritized certain docs. That feedback directly shapes how we tune the system. Open an issue on GitHub to let us know.
Appreciate you for reading 🙌
Appendix: How We Benchmark
The numbers at the top of this post come from our internal benchmark suite. Here's how it works:
Question sets: We wrote 80+ coding questions across popular libraries—Next.js, FastAPI, Playwright, tRPC, Docker, and more. These are the kinds of questions developers typically ask when building with these tools.
Simulation: For each question, we run it through Claude Haiku with Context7 MCP tools available. The model decides when to call resolve-library-id and get-docs, just like it would in a real coding session.
What we measure:
- Tool calls: How many times the LLM called Context7 tools
- Context tokens: Estimated tokens consumed by documentation returned
- Duration: Total time from question to final answer
Quality scoring: After each simulation, we use a separate LLM (Claude Sonnet) to evaluate how helpful and relevant the returned context was on a 1-10 scale. The scoring prompt asks whether the context covers the question, has relevant examples, and would actually help someone implement what they're asking about.
We run the same question sets against both the old and new architectures, then compare the averages.